回答
零拷贝是一种 I/O 操作优化技术,旨在减少上下文切换和 CPU 的拷贝时间。在传统的数据传输过程中,数据从一个存储区域复制(传输)到另一个存储区域需要经历 4 次上下文切换和 2 次 CPU 拷贝,这大大降低了数据传输的效率。而零拷贝通过减少一些不必要的步骤来优化这一过程。目前 Linux 中有如下几种技术来实现:
mmap:mmap允许应用程序通过创建一个文件或设备在内存中的映射,直接访问硬件内存。这样,应用程序可以直接读写这块内存区域,而无需执行系统调用或进行数据拷贝。数据可以从存储设备直接映射到用户空间内存,减少了从内核空间到用户空间的拷贝操作。sendfile:sendfile可以直接在内核中将数据从文件系统缓冲区传输到套接字缓冲区,避免了数据在用户空间和内核空间之间的多次拷贝。sendfile+SG-DMA:真正实现了零拷贝的技术。需要网卡支持SG-DMA技术,这样就可以不需要将内核缓冲区的数据拷贝到套接字缓冲区,由DMA将数据直接从内核缓冲区拷贝到网卡中,一次 CPU 拷贝都不需要。
详解
数据拷贝基础
各位小伙伴应该都写过读写文件的应用程序吧?我们一般都是从磁盘读取文件,然后加工数据,最后写入数据库或发送给其他子系统。

那当中具体的流程是怎么样的?
- 应用程序发起
read()调用,由用户态进入内核态。 - CPU 向磁盘发起 I/O 读取请求。
- 磁盘将数据写入到磁盘缓冲区后,向 CPU 发起 I/O 中断,报告 CPU 数据已经准备好了。
- CPU 将数据从磁盘缓冲区拷贝至内核缓冲区,然后从内核缓冲区将数据拷贝至用户缓冲区
- 完成后,
read()返回,由内核态切换到用户态。
如下:
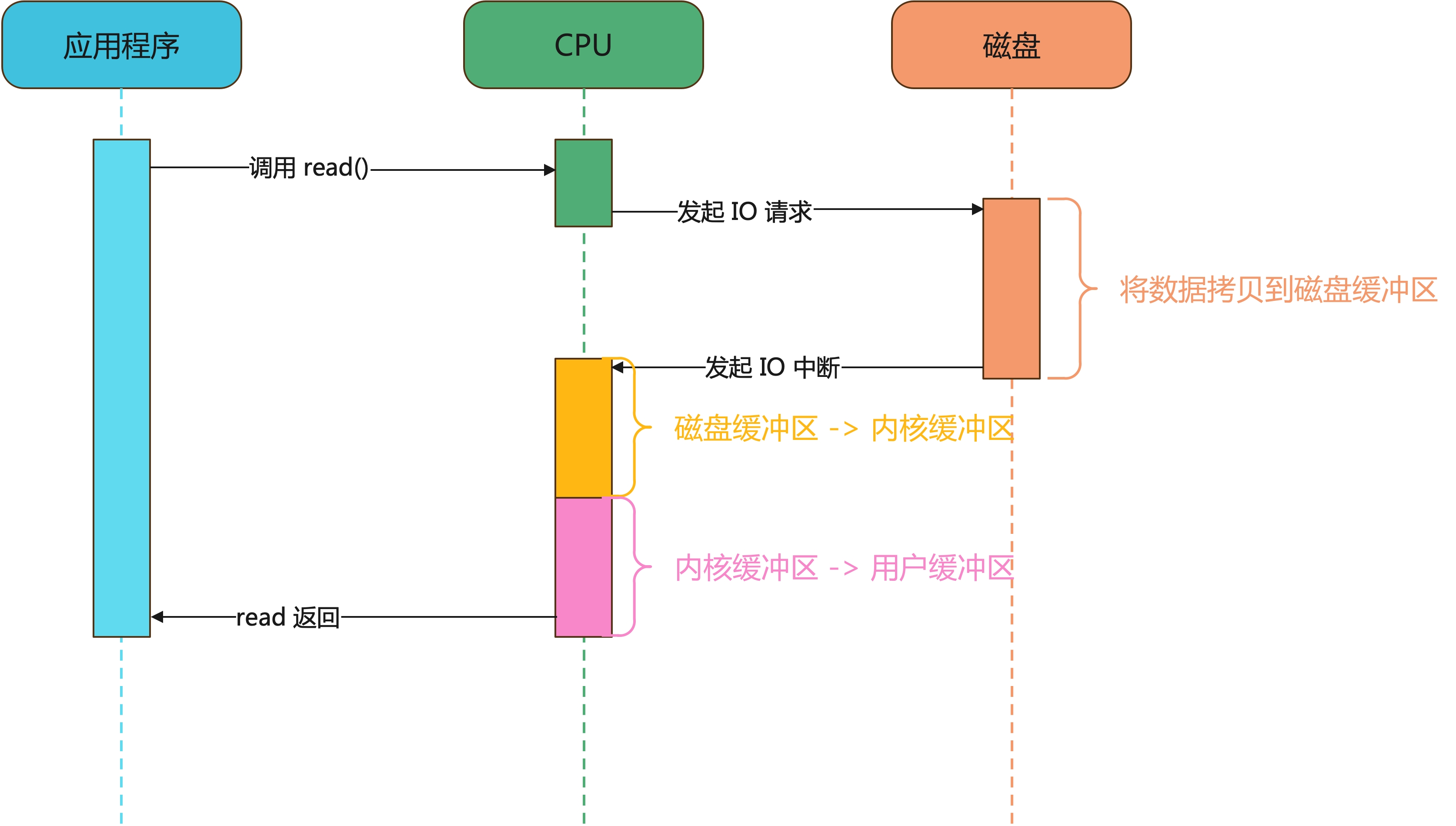
这个过程有一个比较严重的问题就是 CPU 全程参与数据拷贝的过程,而且整个过程 CPU 都不能干其他活,这不是浪费资源,耽误事吗!
怎么解决?引入 DMA 技术,即直接存储器访问(Direct Memory Access),那什么是 DMA 呢?
DMA传输:将数据从一个地址空间复制到另一个地址空间,提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。
我们都知道 CPU 是很稀缺的资源,需要力保它时刻都在处理重要的事情,一些不重要的事情(比如数据复制和存储)就不需要 CPU 参与了,让他去处理更加重要的事情,这样是不是就可以更好地利用 CPU 资源呢?
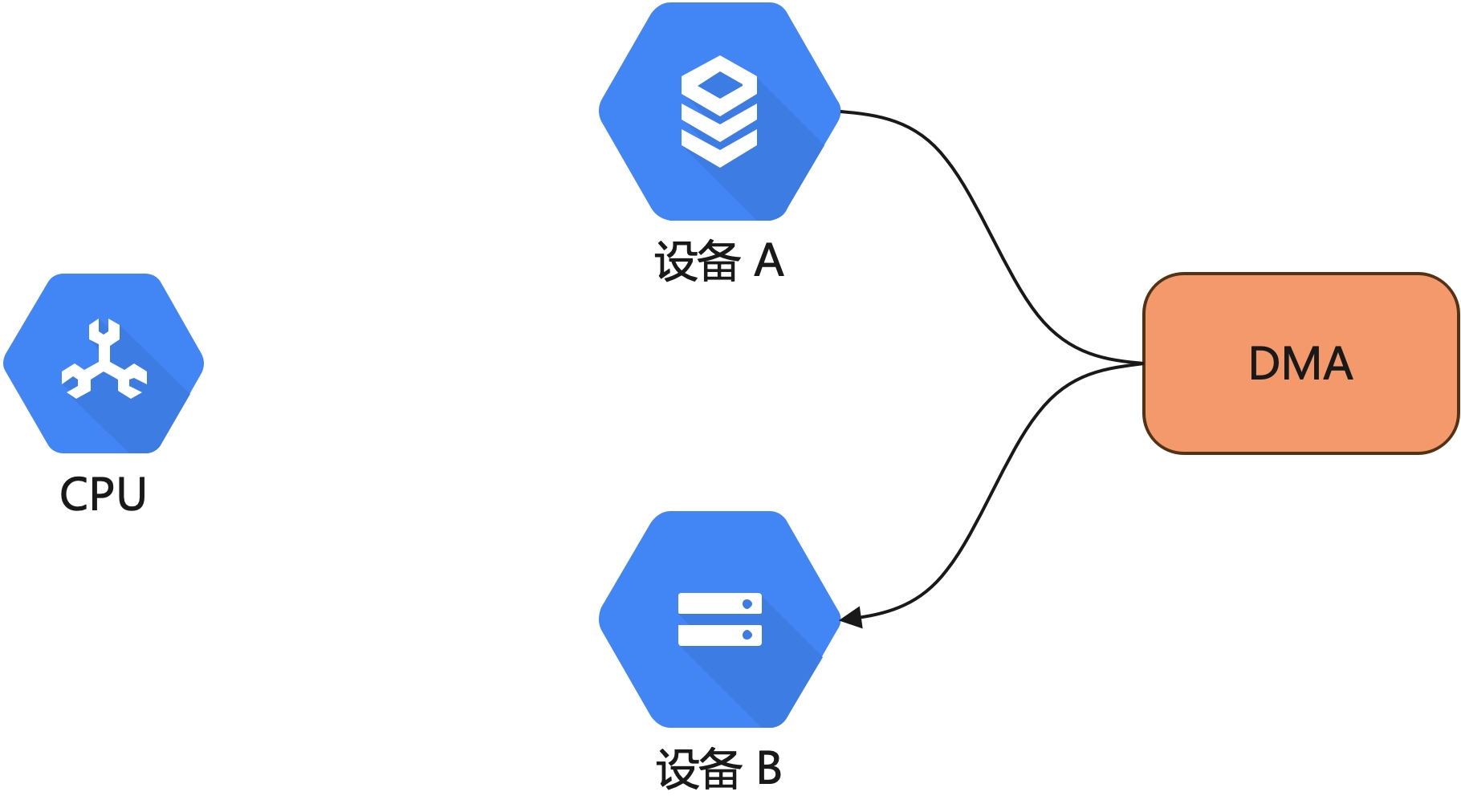
所以,对于我们读取文件(尤其是大文件)这种不那么重要且繁琐的事情是可以不需要 CPU 参与了,我们只需要在两个设备之间建立一种通道,直接由设备 A 通过 DMA 拷贝数据到设备 B,如下图:
加入 DMA 后,数据传输过程就变成下图:
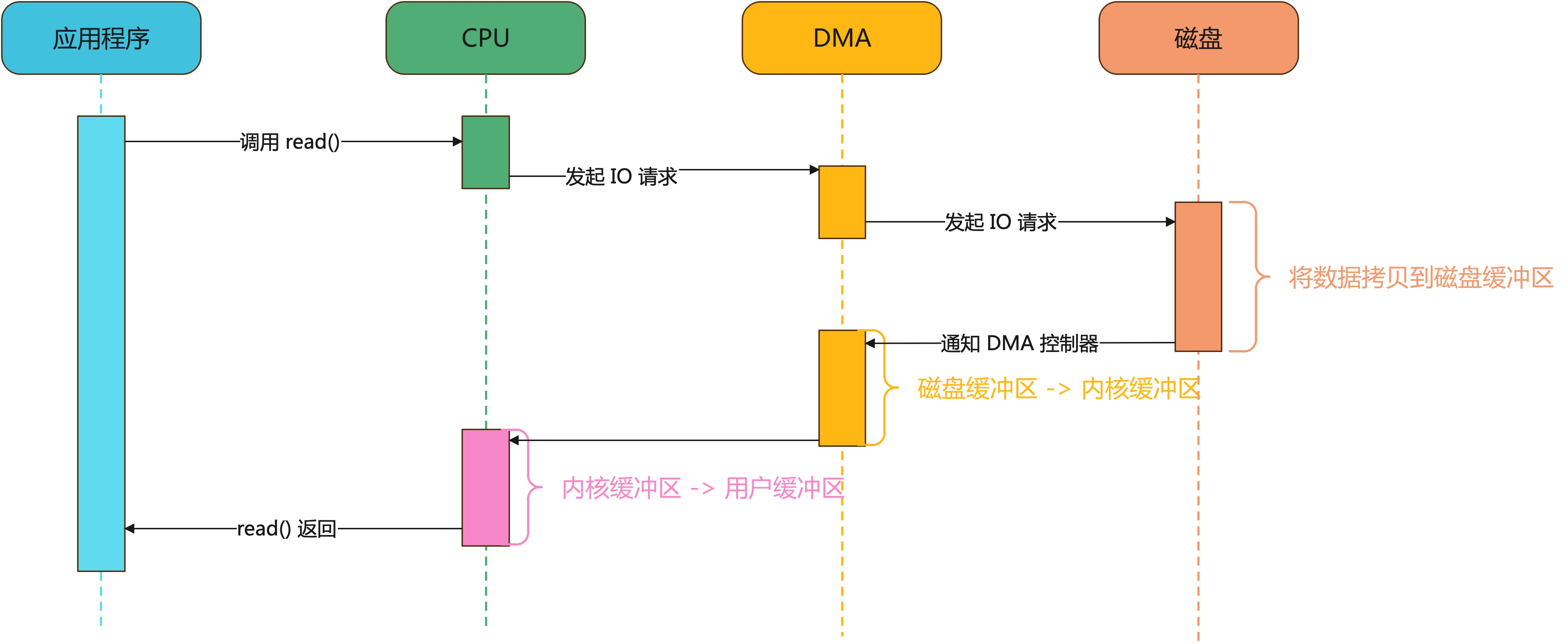
CPU 接收 read() 请求,将 I/O 请求发送给 DMA,这个时候 CPU 就可以去干其他的事情了,等到 DMA 读取足够数据后再向 CPU 发送 IO 中断,CPU 将数据从内核缓冲区拷贝到用户缓冲区,这个数据传输过程,CPU 不再与磁盘打交道了,不再参与数据搬运过程了,由 DMA 来处理。
但是,这样就完了吗?仔细再研究上面的图,就算我们加入了 DMA,整个过程也依然进行了两次内核态&用户态的切换,一次数据拷贝的过程,这还只是读取过程,如果再加上写入呢?性能将会进一步降低。
为什么需要零拷贝
为什么需要零拷贝?因为如果不用它就会慢,性能堪忧啊。体现在哪里呢?我们来看看一次完整的读写数据交互过程有多复杂。下面是应用程序完成一次读写操作的过程图:
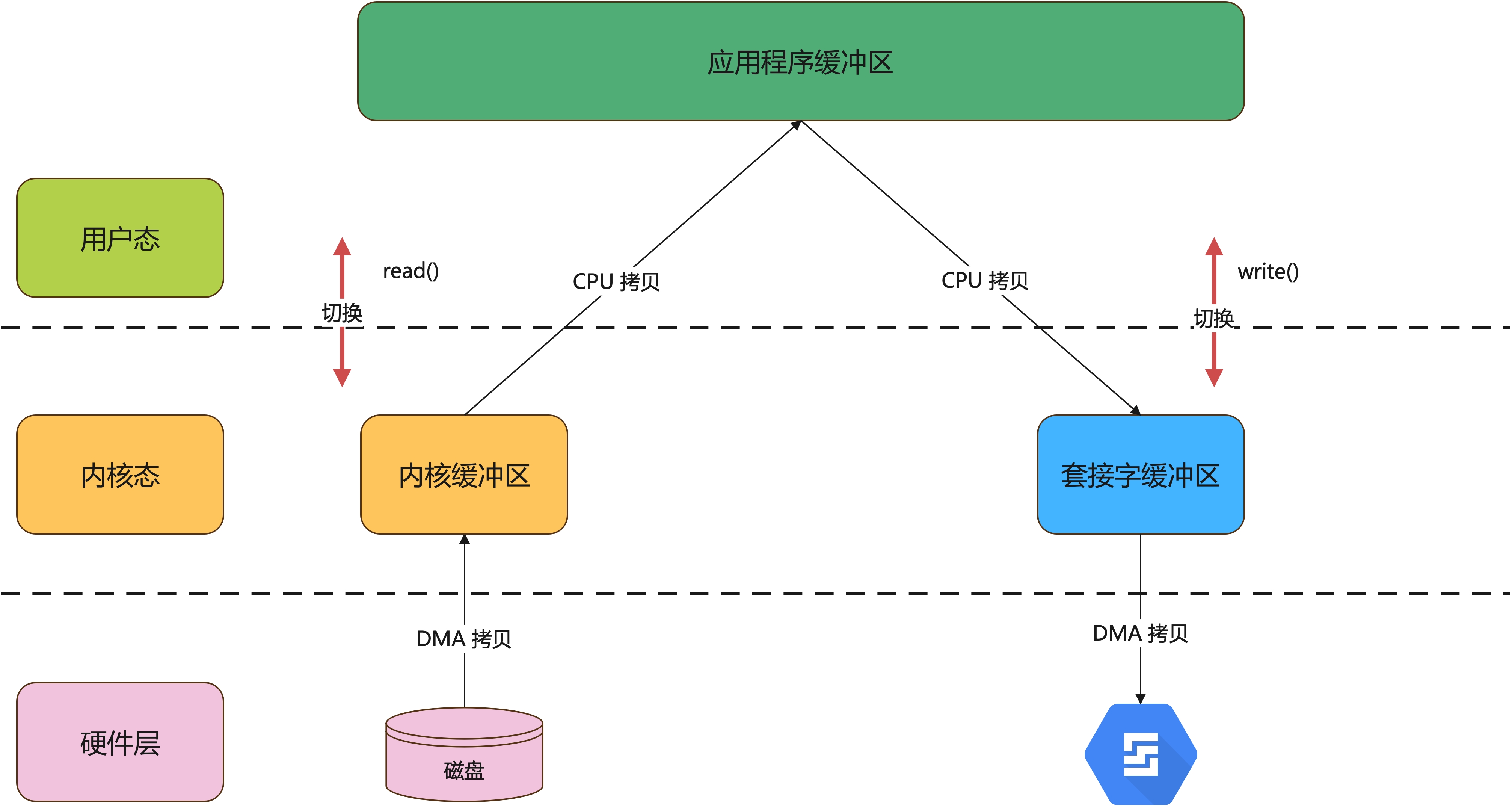
- 读数据过程如下:
| 步骤 | 分析 | |
|---|---|---|
应用程序调用 read() 函数,读取磁盘数据 |
用户态切换至内核态 | 第 1 次切换 |
| DMA 控制器将数据从磁盘拷贝到内核缓冲区 | DMA 拷贝 | 第 1 次 DMA 拷贝 |
| CPU 将数据从内核缓冲区拷贝到用户缓冲区 | CPU 拷贝 | 第 1 次 CPU 拷贝 |
CPU 拷贝完成后,read() 返回 |
内核态切换至用户态 | 第 2 次切换 |
- 写数据过程
| 步骤 | 分析 | |
|---|---|---|
应用程序调用 write()向网卡写入数据 |
用户态切换至内核态 | 第 3 次切换 |
| CPU 将数据从用户缓冲区拷贝到套接字缓冲区 | CPU 拷贝 | 第 2 次 DMA 拷贝 |
| DMA 控制器将数据从内核缓冲区拷贝到网卡 | DMA 拷贝 | 第 2 次 DMA 拷贝 |
完成拷贝后,write() 返回 |
内核态切换至用户态 | 第 4 次切换 |
整个过程进行了 4 次切换,2 次 CPU 拷贝,2 次 DMA 拷贝,效率并不是很高,那怎么提高性能呢?
- 减少用户态和内核态的切换
- 减少拷贝过程
所以零拷贝就出现了。
Linux 的零拷贝
目前实现零拷贝的技术有三种,分别为:
- mmap+write
- sendfile
- sendfile + SG-DMA
下面大明哥依次介绍这些。
mmap+write
mmap 是一种内存映射文件的机制,它实现了将内核中读缓冲区地址与用户空间缓冲区地址进行映射,从而实现内核缓冲区与用户缓冲区的共享。mmap 可以替代 read(),从而减少一次 CPU 拷贝(内核缓冲区 → 应用程序缓冲区)
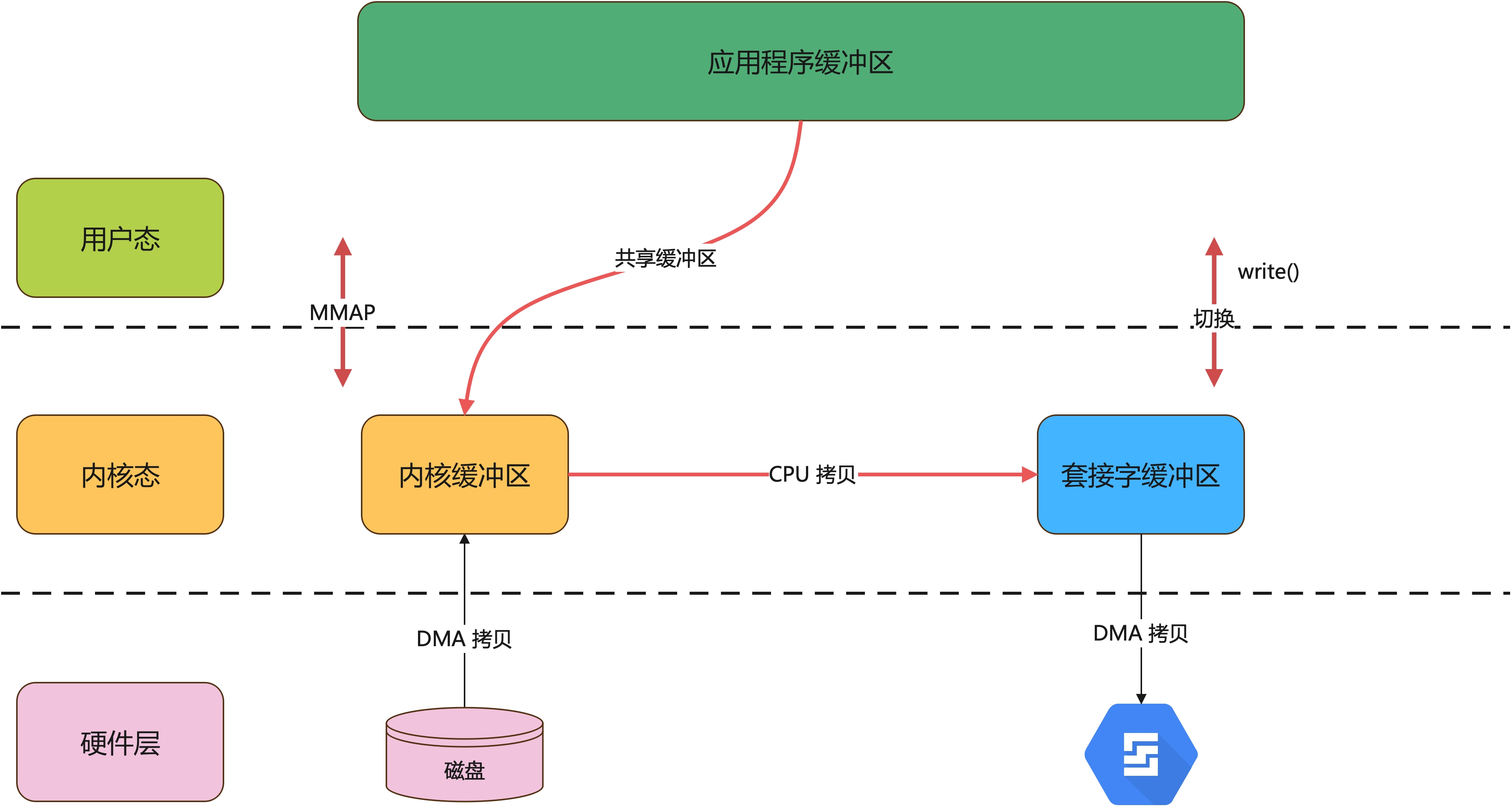
过程如下:
| 步骤 | 分析 | |
|---|---|---|
| 应用程序调用 mmap 读取磁盘数据 | 用户态切换至内核态 | 第 1 次切换 |
| DMA 控制器将数据从磁盘拷贝到内核缓冲区 | DMA 拷贝 | 第 1 次 DMA 拷贝 |
| CPU 拷贝完成后,mmap 返回 | 内核态切换至用户态 | 第 2 次切换 |
- 写数据过程
| 步骤 | 分析 | |
|---|---|---|
应用程序调用 write()向外设写入数据 |
用户态切换至内核态 | 第 3 次切换 |
| CPU 将数据从内核缓冲区拷贝到套接字缓冲区 | CPU 拷贝 | 第 1 次 CPU 拷贝 |
| DMA 控制器将数据从内核缓冲区拷贝到网卡 | DMA 拷贝 | 第 2 次 DMA 拷贝 |
完成拷贝后,write() 返回 |
内核态切换至用户态 | 第 4 次切换 |
mmap 替代了 read(),只减少了一次 CPU 拷贝,依然存在 4 次用户状态&内核状态的上下文切换和 3 次拷贝,整体来说还不是这么理想。
sendfile
sendfile 是 Linux2.1 内核版本后引入的一个系统调用函数,专门用来发送文件的函数,它建立了文件的传输通道,数据直接从设备 A 传输到设备 B,不需要经过用户缓冲区。
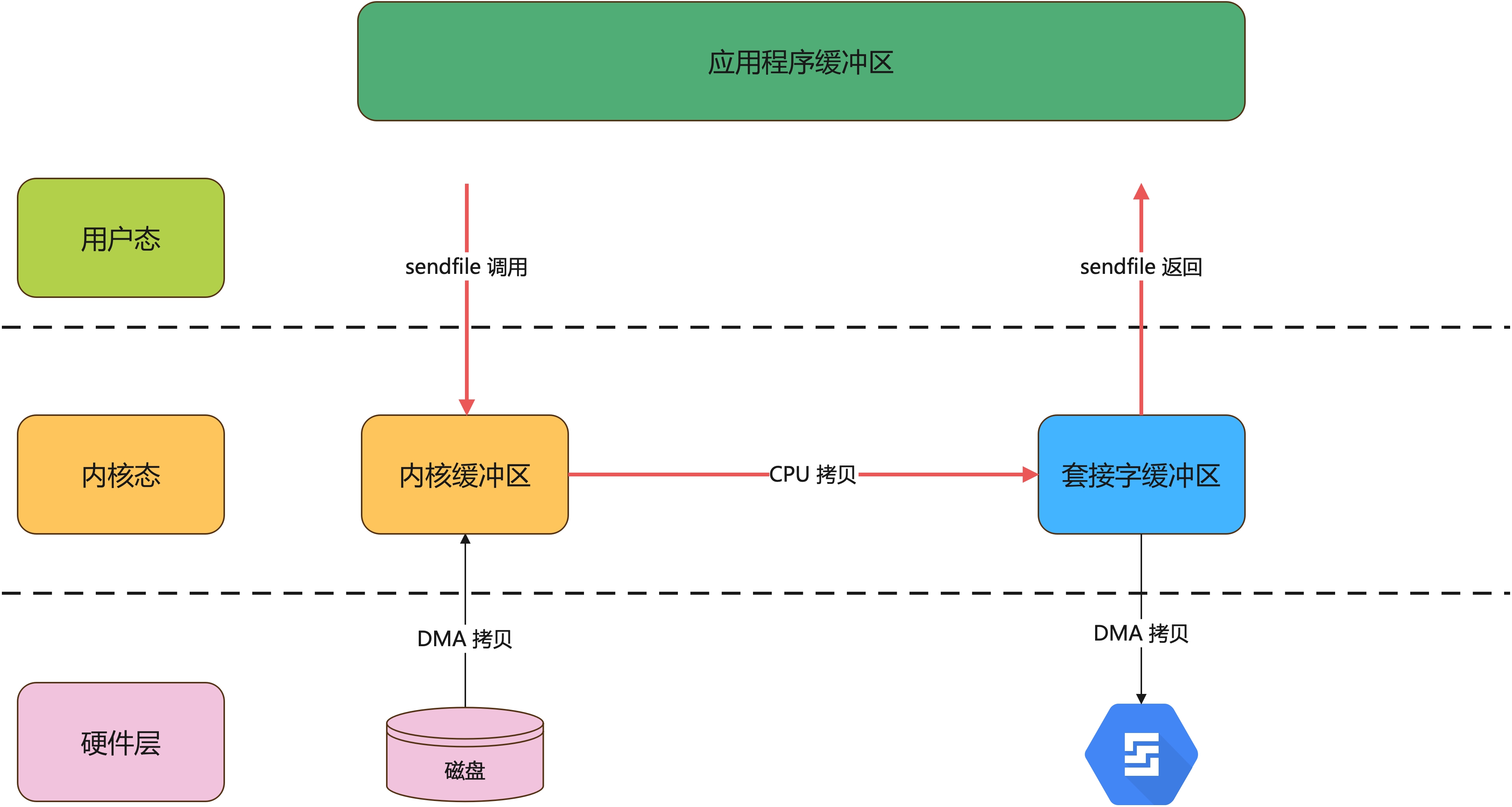
使用 sendfile 就直接替换了上面的 read() 和 write() 两个函数,这样就只需要需要进行两次切换。如下:
| 步骤 | 分析 | |
|---|---|---|
应用程序调用 sendfile |
用户态切换至内核态 | 第 1 次切换 |
| DMA 把数据从磁盘拷贝到内核缓冲区 | DMA 拷贝 | 第 1 次 DMA 拷贝 |
| CPU 把数据从内核缓冲区拷贝到套接字缓冲区 | CPU 拷贝 | 第 1 次 CPU 拷贝 |
| DMA 把数据从套接字缓冲区拷贝到网卡 | DMA 拷贝 | 第 2 次 DMA 拷贝 |
| 完成后,sendfile 返回 | 内核态切换至用户态 | 第 2 次切换 |
这个技术比传统的减少了 2 次用户态&内核态的上下文切换和一次 CPU 拷贝。
但是,它有一个缺陷就是因为数据不经过用户缓冲区,所以无法修改数据,只能进行文件传输。
sendfile + SG-DMA
Linux 2.4 内核版本对sendfile做了进一步优化,如果网卡支持 SG-DMA(The Scatter-Gather Direct Memory Access)技术,我们可以不需要将内核缓冲区的数据拷贝到套接字缓冲区。
它将内核缓冲区的数据描述信息(文件描述符、偏移量等信息)记录到套接字缓冲区,由 DMA 根据这些数据从内核缓冲区拷贝到网卡中,从而再一次减少 CPU 拷贝。
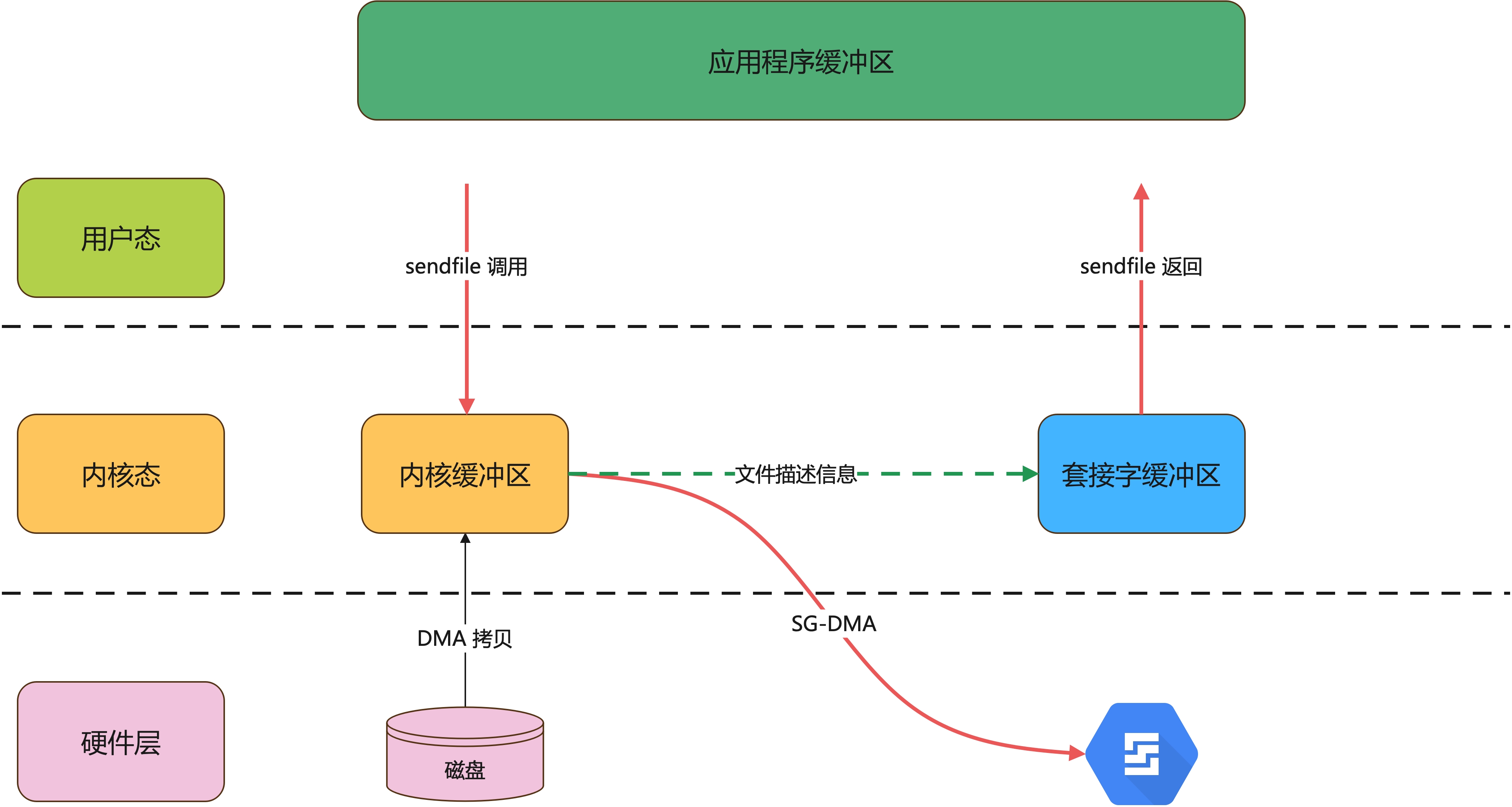
过程如下:
| 步骤 | 分析 | |
|---|---|---|
应用程序调用 sendfile |
用户态切换至内核态 | 第 1 次切换 |
| DMA 把数据从磁盘拷贝到内核缓冲区 | DMA 拷贝 | 第 1 次 DMA 拷贝 |
| SG-DMA 把数据从内核缓冲区拷贝到网卡 | DMA 拷贝 | 第 2 次 DMA 拷贝 |
sendfile 返回 |
内核态切换至用户态 | 第 2 次切换 |
这个过程已经没有了 CPU 拷贝了,也只有 2 次上下文件切换,这就是真正的零拷贝技术,全程无 CPU 参与,所有数据的拷贝都依靠 DMA 来完成。
最后
最后做一个总结:
| 技术类型 | 上下文切换次数 | CPU 拷贝次数 | DMA 拷贝次数 |
|---|---|---|---|
read() + write() |
4 | 2 | 2 |
mmap + write() |
4 | 1 | 2 |
sendfile() |
2 | 1 | 2 |
sendfile() + SG-DMA |
2 | 0 | 2 |
零拷贝比传统的 read() + write() 方式减少了 2 次上下文切换和 2 次 CPU 拷贝,性能至少提升了 1 倍。
