producer端设计
1、producer端基本数据结构
新版本客户端(包含新版本producer和新版本consumer)重写了之前服务器端代码提供的很多数据结构,以摆脱对服务器端代码的依赖。其中有一些是理解新版本producer设计所必需的,它们包括(但不限于)如下这些。
1.1、ProducerRecord
一个ProducerRecord封装了一条待发送的消息(或称为记录)。虽然Kafka0.1l.0.0版本对消息格式进行了部分重构以支持事务和精确一次处理语义,但将以0.10.2.1版本的
消息格式进行producer的说明。
ProducerRecord由5个字段构成,它们分别如下。
- topic:该消息所属的topic.
- partition:该消息所属的分区。
- key:消息key。
- value:消息体。
- timestamp:消息时间戳。
ProducerRecord允许用户在创建消息对象的时候直接指定要发送的分区,这样producer后续发送该消息时可以直接发送到指定分区,而不用先通过Partitioner计算目标分区。另外,我们还可以直接指定消息的时间戳一但一定要慎重使用这个功能,因为它有可能会令时间戳索引机制失效。
1.2、RecordMetadata
该数据结构表示Kafka服务器端返回给客户端的消息的元数据信息,包含如下内容。
- offset:消息在分区日志中的位移信息。
- timestamp:消息时间戳。
- topic/partition:所属topic的分区。
- checksum:消息CRC32码。
- serializedKeySize:序列化后的消息key字节数。
- serializedValueSize:序列化后的消息value字节数。
上面的元数据信息的前3项信息是比较重要的,producer端可以使用这些信息做一些消息发送成功之后的处理,比如写入日志等。
2、工作流程
如果把producer统一看成一个盒子,那么整个producer端的工作原理便如图6.51所示。大体上来说,用户首先构建待发送的消息对象ProducerRecord,然后调用KafkaProducer#send方法进行发送。KafkaProducer接收到消息后首先对其进行序列化,然后结合本地缓存的元数据信息一起发送给partitioner去确定目标分区,最后追加写入内存中的消息缓冲池(accumulator)。此时KafkaProducer#send方法成功返回。
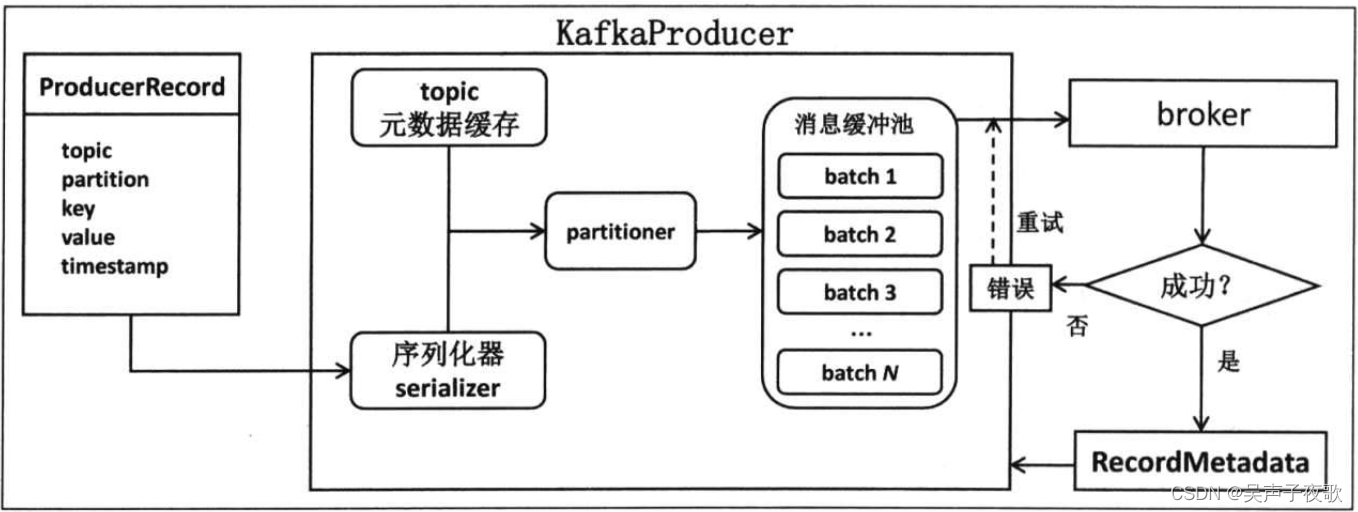
KafkaProducer中还有一个专门的Sender I/O线程负责将缓冲池中的消息分批次发送给对应的broker,完成真正的消息发送逻辑。
图中其实并没有深入展开producer的工作原理。这里说说producer内部到底是如何工作的,也就是梳理一下当用户调用KafkaProducer…send(ProducerRecord,Callback)时Kafka内部都发生了什么事情。
第一步:序列化+计算目标分区。
这是KafkaProducer#send逻辑的第一步,即为待发送消息进行序列化并计算目标分区,如图所示。

如图所示,一条所属topic是"test",消息体是"message"的消息被序列化之后结合KafkaProducer缓存的元数据(比如该topic分区数信息等)共同传给后面的Partitioner实现类
进行目标分区的计算。
第二步:追加写入消息缓冲区(accumulator)。
producer创建时会创建一个默认32MB(由buffer.memory参数指定)的accumulator缓冲区,专门保存待发送的消息。除了之前在“关键参数”部分中提到的linger.ms和batch.size等参数之外,该数据结构中还包含了一个特别重要的集合信息:消息批次信息(batches)。该集合本质上是一个HashMap,里面分别保存了每个topic分区下的batch队列,即前面说的批次是按照topic分区进行分组的。这样发往不同分区的消息保存在对应分区下的batch队列中。举一个简单的例子,假设消息M1、M2被发送到test的0分区但属于不同的batch,M3被发送到test的1分区,那么batches中包含的信息就是{“test-0”->[batch1,batch2],“test-l”->[batch.3]}。
单个topic分区下的batch队列中保存的是若干个消息批次,每个batch中最重要的3个组件如下。
- compressor:负责执行追加写入操作。
- batch缓冲区:由batch.size参数控制,消息被真正追加写入的地方。
- thunks:保存消息回调逻辑的集合。
这一步的目的就是将待发送的消息写入消息缓冲池中,具体流程如图所示。
这一步执行完毕之后理论上讲KafkaProducer…send方法就执行完毕了,用户主线程所做的事情就是等待Sender线程发送消息并执行返回结果。
第三步:Sender线程预处理及消息发送。
此时,该Sender线程登场了。严格来说,Sender线程自KafkaProducer创建后就一直都在运行着。它的工作流程基本上是如下这样的。

- 不断轮询缓冲区寻找已做好发送准备的分区。
- 将轮询获得的各个batch按照目标分区所在的leader broker进行分组。
- 将分组后的batch通过底层创建的Socket连接发送给各个broker。
- 等待服务器端发送response回来。

第四步:Sender线程处理response.
图中Sender线程会发送PRODUCE请求给对应的broker,broker处理完毕之后发送对应的PRODUCE response。一旦Sender线程接收到response,将依次(按照消息发送顺序)调用batch中的回调方法,如图所示。

做完这一步,producer发送消息的工作就可以算作100%完成了。通过这4步我们可以看到新版本producer发送事件完全是异步过程。因此在调优producer前我们需要搞清楚性能瓶颈到底是在用户主线程上还是在Sender线程上。
