大致流程图

获取全量服务信息
我们来讲下客户端获取全量服务信息的时候服务端是怎么做的。调用的是ApplicationsResource的getContainers。主要就是创建一个缓存的Key对象,对象的属性值ResponseCacheImpl.ALL_APPS表示的就是全量,也就是获取缓存用的,缓存其实是个map。然后调用responseCache.getGZIP获取全量的服务信息。
@GET
public Response getContainers(@PathParam("version") String version,
@HeaderParam(HEADER_ACCEPT) String acceptHeader,
@HeaderParam(HEADER_ACCEPT_ENCODING) String acceptEncoding,
@HeaderParam(EurekaAccept.HTTP_X_EUREKA_ACCEPT) String eurekaAccept,
@Context UriInfo uriInfo,
@Nullable @QueryParam("regions") String regionsStr) {
...
//创建一个缓存对象
Key cacheKey = new Key(Key.EntityType.Application,
ResponseCacheImpl.ALL_APPS,//全量
keyType, CurrentRequestVersion.get(), EurekaAccept.fromString(eurekaAccept), regions
);
Response response;
if (acceptEncoding != null && acceptEncoding.contains(HEADER_GZIP_VALUE)) {
response = Response.ok(responseCache.getGZIP(cacheKey))//获取压缩的数据
.header(HEADER_CONTENT_ENCODING, HEADER_GZIP_VALUE)
.header(HEADER_CONTENT_TYPE, returnMediaType)
.build();
} else {
response = Response.ok(responseCache.get(cacheKey))
.build();
}
...
return response;
}
Key缓存的对象
这个对象没什么好看的,就是他重写了hashCode方法,也就是让map可以比对怎么样是同一个对象,map是根据hashCode相关算法比对的:



可见不同的对象,只要传入的属性值相同,那么hashKey相同,hashCode()返回值就相同,在map中认为是同一个Key,就可以获取同一个对象。
ResponseCacheImpl的getGZIP
把Key对象传进去,获取值,默认是用只读缓存的,其实内部有三级缓存,只读,读写,注册表。
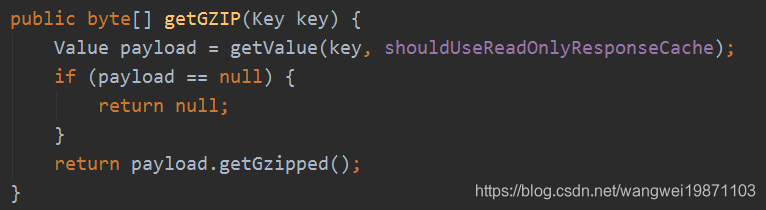
getValue获取值
可以看到,默认先启用读缓存readOnlyCacheMap,如果找到就返回了,否则再看读写缓存readWriteCacheMap,如果写缓存不存在,就会从注册表中获取,这个后面会说这么做的,存在的话就直接返回,然后都要保存到读缓存中。这里为什么要这样设计,读写分离,就是为了提高性能,写的时候不会影响到读,读也不会影响到写,当然这里会用定时器来进行数据的同步,但是不是实时的,为了性能,保证数据最终一致。

这两个缓存的类型,LoadingCache是谷歌缓存框架里的,提供了一个方法,就是不存在的时候要怎么办,这里不存在的时候就可以去注册表中获取:

readWriteCacheMap不存在的处理方式
如果读写缓存不存在,就会去注册表中获取,哪里看出来的呢,创建的时候:

generatePayload
看下面的。

然后直接用JSON编码后返回。

registry.getApplications()做了什么

内部就是获取了注册表的所有信息,封装成Applications对象:

最后计算出AppsHashCode后返回:

registry和Applications的结构大致如图
其实就是做了类型的转换,好编码后发到客户端,数据还是这些数据。

三级缓存基本讲完了,首先是读缓存,然后读写缓存,最后注册表,为了读写分离,后面讲他们怎么进行数据同步的。
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵。
