Redis 的数据全部在内存里,如果突然宕机,数据就会全部丢失,因此必须有一种机制来保证 Redis 的数据不会因为故障而丢失,这种机制就是 Redis 的持久化机制。
Redis 的持久化机制有两种,第一种是快照,第二种是 AOF 日志。快照是一次全量备份,AOF 日志是连续的增量备份。快照是内存数据的二进制序列化形式,在存储上非常紧凑,而 AOF 日志记录的是内存数据修改的指令记录文本。AOF 日志在长期的运行过程中会变的无比庞大,数据库重启时需要加载 AOF 日志进行指令重放,这个时间就会无比漫长。所以需要定期进行 AOF 重写,给 AOF 日志进行瘦身。
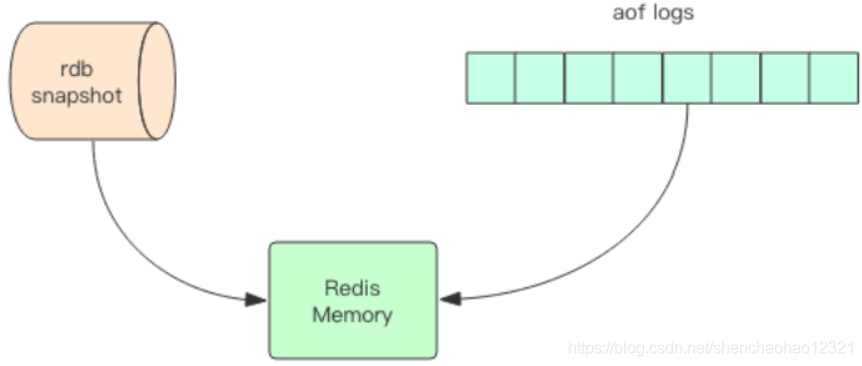
快照原理
我们知道 Redis 是单线程程序,这个线程要同时负责多个客户端套接字的并发读写操作和内存数据结构的逻辑读写。
在服务线上请求的同时,Redis 还需要进行内存快照,内存快照要求 Redis 必须进行文件 IO 操作,可文件 IO 操作是不能使用多路复用 API。
这意味着单线程同时在服务线上的请求还要进行文件 IO 操作,文件 IO 操作会严重拖垮服务器请求的性能。还有个重要的问题是为了不阻塞线上的业务,就需要边持久化边响应客户端请求。持久化的同时,内存数据结构还在改变,比如一个大型的 hash 字典正在持久化,结果一个请求过来把它给删掉了,还没持久化完呢,这尼玛要怎么搞?
那该怎么办呢?
Redis 使用操作系统的多进程 COW(Copy On Write) 机制来实现快照持久化,这个机制很有意思,也很少人知道。多进程 COW 也是鉴定程序员知识广度的一个重要指标。
fork(多进程)
Redis 在持久化时会调用 glibc 的函数 fork 产生一个子进程,快照持久化完全交给子进程来处理,父进程继续处理客户端请求。子进程刚刚产生时,它和父进程共享内存里面的代码段和数据段。这时你可以将父子进程想像成一个连体婴儿,共享身体。这是 Linux 操作系统的机制,为了节约内存资源,所以尽可能让它们共享起来。在进程分离的一瞬间,内存的增长几乎没有明显变化。
用 Python 语言描述进程分离的逻辑如下。fork 函数会在父子进程同时返回,在父进程里返回子进程的 pid,在子进程里返回零。如果操作系统内存资源不足,pid 就会是负数,表示 fork 失败。
pid = os.fork()
if pid > 0:
handle_client_requests() # 父进程继续处理客户端请求
if pid == 0:
handle_snapshot_write() # 子进程处理快照写磁盘
if pid < 0:
# fork error
子进程做数据持久化,它不会修改现有的内存数据结构,它只是对数据结构进行遍历读取,然后序列化写到磁盘中。但是父进程不一样,它必须持续服务客户端请求,然后对内存数据结构进行不间断的修改。
这个时候就会使用操作系统的 COW 机制来进行数据段页面的分离。数据段是由很多操作系统的页面组合而成,当父进程对其中一个页面的数据进行修改时,会将被共享的页面复制一份分离出来,然后对这个复制的页面进行修改。这时子进程相应的页面是没有变化的,还是进程产生时那一瞬间的数据。
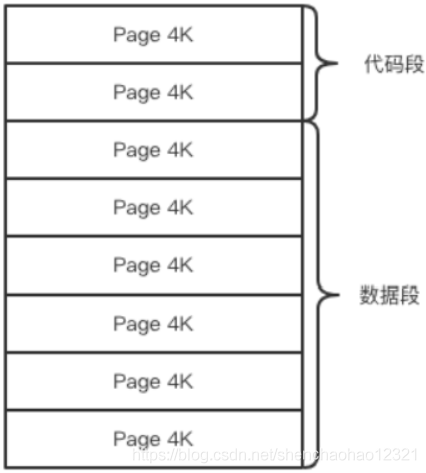
随着父进程修改操作的持续进行,越来越多的共享页面被分离出来,内存就会持续增长。但是也不会超过原有数据内存的 2 倍大小。另外一个 Redis 实例里冷数据占的比例往往是比较高的,所以很少会出现所有的页面都会被分离,被分离的往往只有其中一部分页面。每个页面的大小只有 4K,一个 Redis 实例里面一般都会有成千上万的页面。
子进程因为数据没有变化,它能看到的内存里的数据在进程产生的一瞬间就凝固了,再也不会改变,这也是为什么 Redis 的持久化叫「快照」的原因。接下来子进程就可以非常安心的遍历数据了进行序列化写磁盘了。
AOF 原理
AOF 日志存储的是 Redis 服务器的顺序指令序列,AOF 日志只记录对内存进行修改的指令记录。
假设 AOF 日志记录了自 Redis 实例创建以来所有的修改性指令序列,那么就可以通过对一个空的 Redis 实例顺序执行所有的指令,也就是「重放」,来恢复 Redis 当前实例的内存数据结构的状态。
Redis 会在收到客户端修改指令后,先进行参数校验,如果没问题,就立即将该指令文本存储到 AOF 日志中,也就是先存到磁盘,然后再执行指令。这样即使遇到突发宕机,已经存储到 AOF 日志的指令进行重放一下就可以恢复到宕机前的状态。
Redis 在长期运行的过程中,AOF 的日志会越变越长。如果实例宕机重启,重放整个 AOF 日志会非常耗时,导致长时间 Redis 无法对外提供服务。所以需要对 AOF 日志瘦身。
AOF 重写
Redis 提供了 bgrewriteaof 指令用于对 AOF 日志进行瘦身。其原理就是开辟一个子进程对内存进行遍历转换成一系列 Redis 的操作指令,序列化到一个新的 AOF 日志文件中。
序列化完毕后再将操作期间发生的增量 AOF 日志追加到这个新的 AOF 日志文件中,追加完毕后就立即替代旧的 AOF 日志文件了,瘦身工作就完成了。
fsync
AOF 日志是以文件的形式存在的,当程序对 AOF 日志文件进行写操作时,实际上是将内容写到了内核为文件描述符分配的一个内存缓存中,然后内核会异步将脏数据刷回到磁盘的。
这就意味着如果机器突然宕机,AOF 日志内容可能还没有来得及完全刷到磁盘中,这个时候就会出现日志丢失。那该怎么办?
Linux 的 glibc 提供了 fsync(int fd)函数可以将指定文件的内容强制从内核缓存刷到磁盘。只要 Redis 进程实时调用 fsync 函数就可以保证 aof 日志不丢失。但是 fsync 是一个磁盘 IO 操作,它很慢!如果 Redis 执行一条指令就要 fsync 一次,那么 Redis 高性能的地位就不保了。
所以在生产环境的服务器中,Redis 通常是每隔 1s 左右执行一次 fsync 操作,周期 1s 是可以配置的。这是在数据安全性和性能之间做了一个折中,在保持高性能的同时,尽可能使得数据少丢失。
Redis 同样也提供了另外两种策略,一个是永不 fsync——让操作系统来决定合适同步磁盘,很不安全,另一个是来一个指令就 fsync 一次——非常慢。但是在生产环境基本不会使用,了解一下即可。
运维
快照是通过开启子进程的方式进行的,它是一个比较耗资源的操作。
1、遍历整个内存,大块写磁盘会加重系统负载
2、AOF 的 fsync 是一个耗时的 IO 操作,它会降低 Redis 性能,同时也会增加系统 IO 负担
所以通常 Redis 的主节点是不会进行持久化操作,持久化操作主要在从节点进行。从节点是备份节点,没有来自客户端请求的压力,它的操作系统资源往往比较充沛。
但是如果出现网络分区,从节点长期连不上主节点,就会出现数据不一致的问题,特别是在网络分区出现的情况下又不小心主节点宕机了,那么数据就会丢失,所以在生产环境要做好实时监控工作,保证网络畅通或者能快速修复。另外还应该再增加一个从节点以降低网络分区的概率,只要有一个从节点数据同步正常,数据也就不会轻易丢失。
Redis 4.0 混合持久化
重启 Redis 时,我们很少使用 rdb 来恢复内存状态,因为会丢失大量数据。我们通常使用 AOF 日志重放,但是重放 AOF 日志性能相对 rdb 来说要慢很多,这样在 Redis 实例很大的情况下,启动需要花费很长的时间。
Redis 4.0 为了解决这个问题,带来了一个新的持久化选项——混合持久化。将 rdb 文件的内容和增量的 AOF 日志文件存在一起。这里的 AOF 日志不再是全量的日志,而是自持久化开始到持久化结束的这段时间发生的增量 AOF 日志,通常这部分 AOF 日志很小。
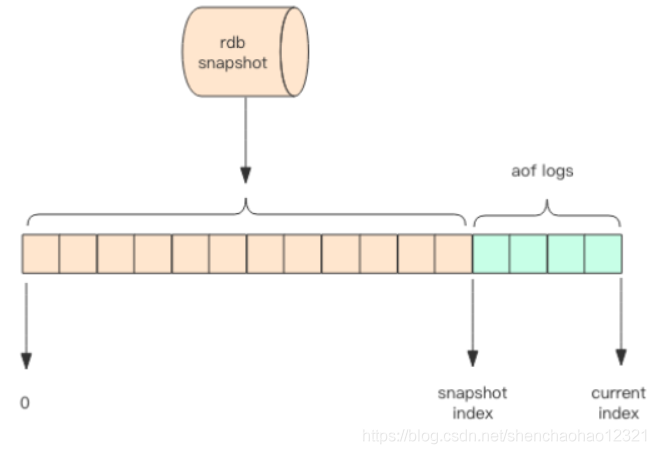
于是在 Redis 重启的时候,可以先加载 rdb 的内容,然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放,重启效率因此大幅得到提升。
思考题
有人说 Redis 只适合用来做缓存,当数据库来用并不合适,你怎么看?
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
