本章,我将对分布式文件系统的 可扩展 架构进行讲解。我们知道,对于一个分布式系统来说,可扩展意味着能够自由伸缩。那么,对应到我们的分布式文件系统的场景,就是:
- 当DataNode集群的存储容量快满了以后,通过新增DataNode节点,可以实现水平动态扩容;
- 当DataNode集群中的某个节点下线后,该节点上的文件会自动重分配到其它节点上。
上述两个过程,本质就是分布式存储系统的 Rebalance机制 。关于第二点,我已经在高可用架构中的 文件副本重分配 中讲解过了,本章,我们重点关注如何实现DataNode节点的水平扩容。
本节涉及得代码存放在:https://gitee.com/ressmix/source-code/tree/master/5.dfs/4.scalable。
一、Rebalance机制
我们的分布式文件系统是双副本机制,所以每次扩容的机器数,要求是 2的倍数 。
由于NameNode会在内存中维护整个DataNode集群的元数据信息,并根据DataNode的心跳、增量上报、全量上报请求更新元数据。所以,NameNode可以计算出整个集群的平均容量,然后根据每个DataNode节点的容量,选择出合适的源节点和目标节点,并对源节点上的每个文件创建副本复制任务,最后通过心跳下发给目标节点。
整个流程其实复用了高可用架构中的 文件副本重分配 机制。
1.1 整体流程
举个例子来理解,假设我们现在有4台DataNode机器,每台机器已使用的容量如下:
- 机器01:90GB
- 机器02:90GB
- 机器03:90GB
- 机器04:90GB
现在,我们需要扩容2台机器:
- 机器05:0GB
- 机器06:0GB
那么,机器05和06启动后,会自动向NameNode注册自己的信息。整个扩容流程可以用下面这张图来表示:
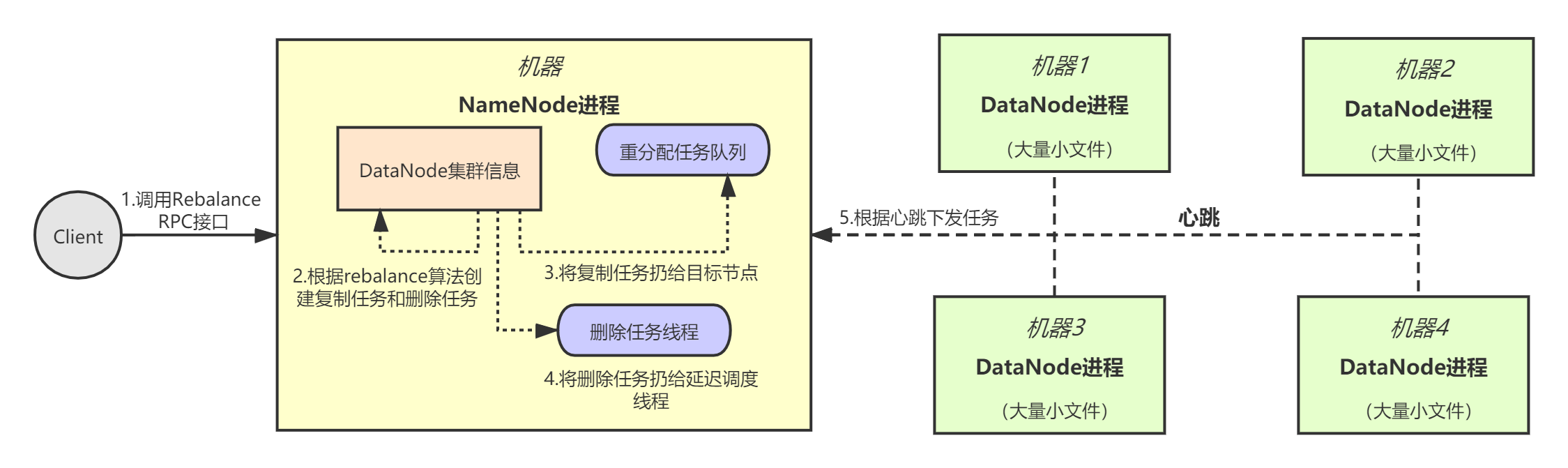
正常情况下,Rebalance通过手动触发,我们可以让NameNode提供一个RPC服务接口——rebalance,当NameNode接收到Rebalance RPC请求后,就执行Rebalance流程:
- 首先,NameNode根据内存中的DataNode集群信息,计算平均容量;
- 接着,NameNode根据每个DataNode节点的已用容量,选择出目标节点和源节点,并创建 文件复制任务 到队列中,文件需要从源节点复制到目标节点上。同时,针对源节点,还要创建延迟调度的 文件删除任务 ;
- 当目标DataNode发送心跳时,获取到文件复制任务,于是与源节点建立连接,完成文件复制。
- 最后,一段时间后触发文件删除任务,源节点将自己服务器上的指定文件删除掉。
1.2 Rebalance RPC接口
首先,我们需要新增一个Rebalance接口:
syntax = "proto3";
option java_multiple_files = true;
option java_outer_classname = "NameNodeServiceProto";
service NameNodeService {
//...
rpc rebalance(RebalanceRequest) returns (RebalanceResponse){}
}
message RebalanceRequest{
int32 status = 1;
}
message RebalanceResponse{
int32 status = 1;
}
//...
NameNode接受到Rebalance RPC请求后,调用DataNodeManager.rebalance()方法触发Rebalance机制:
// NameNodeServiceImpl.java
/**
* DataNode集群Rebalance
*/
@Override
public void rebalance(RebalanceRequest request, StreamObserver<RebalanceResponse> responseObserver) {
RebalanceResponse response = null;
try {
datanodeManager.rebalance();
response = RebalanceResponse.newBuilder().setStatus(STATUS_SUCCESS).build();
} catch (Exception e) {
e.printStackTrace();
response = RebalanceResponse.newBuilder().setStatus(STATUS_FAILURE).build();
}
responseObserver.onNext(response);
responseObserver.onCompleted();
}
二、Rebalance算法
Rebalance的主体流程在DataNodeManager.rebalance()方法中实现。整个算法的思路是比较简单的,核心思想就是: 根据集群容量,计算出源节点和目标节点,对于源节点中的每个文件创建一个文件复制任务下发给目标节点,创建一个延迟文件删除任务给源节点 :
// DataNodeManager.java
/**
* DataNode集群rebalance
*/
public void rebalance() {
synchronized (this) {
// 1.计算DataNode集群容量平均值
long totalStoredDataSize = 0;
for (DataNodeInfo datanode : datanodes.values()) {
totalStoredDataSize += datanode.getStoredDataSize();
}
long averageStoredDataSize = totalStoredDataSize / datanodes.size();
// 2.将集群节点分为两类:source迁出节点(大于平均值)和dest迁入节点(小于平均值)
List<DataNodeInfo> sourceDatanodes = new ArrayList<>();
List<DataNodeInfo> destDatanodes = new ArrayList<>();
for (DataNodeInfo datanode : datanodes.values()) {
// 已存储容量大于平均值的作为source迁出节点
if (datanode.getStoredDataSize() > averageStoredDataSize) {
sourceDatanodes.add(datanode);
}
// 已存储容量小于平均值的作为dest迁入节点
if (datanode.getStoredDataSize() < averageStoredDataSize) {
destDatanodes.add(datanode);
}
}
// 3.为dest节点生成复制任务,为source节点生成删除任务
List<RemoveReplicaTask> removeReplicaTasks = new ArrayList<>();
for (DataNodeInfo sourceDatanode : sourceDatanodes) {
long toRemoveDataSize = sourceDatanode.getStoredDataSize() - averageStoredDataSize;
for (DataNodeInfo destDatanode : destDatanodes) {
// 找到一个能够容纳的dest节点
if (destDatanode.getStoredDataSize() + toRemoveDataSize <= averageStoredDataSize) {
createRebalanceTasks(sourceDatanode, destDatanode,
removeReplicaTasks, toRemoveDataSize);
break;
} else {
long maxRemoveDataSize = averageStoredDataSize - destDatanode.getStoredDataSize();
long removedDataSize = createRebalanceTasks(sourceDatanode, destDatanode,
removeReplicaTasks, maxRemoveDataSize);
toRemoveDataSize -= removedDataSize;
}
}
}
// 交给一个延迟线程去24小时之后执行删除副本的任务
new DelayRemoveReplicaThread(removeReplicaTasks).start();
}
}
2.1 文件复制任务
我们来看下具体的createRebalanceTasks代码,它在内部创建了文件复制任务ReplicateTask和文件删除任务
// DataNodeManager.java
/**
* 创建rebalance任务
*/
private long createRebalanceTasks(DataNodeInfo sourceDatanode, DataNodeInfo destDatanode,
List<RemoveReplicaTask> removeReplicaTasks, long maxRemoveDataSize) {
// 1.列出源节点的所有文件
List<String> files = fileMappedByDataNode.get(sourceDatanode);
// 2.遍历文件,为每个文件生成一个复制任务
long removedDataSize = 0;
for (String file : files) {
String filename = file.split("_")[0];
long fileLength = Long.valueOf(file.split("_")[1]);
if (removedDataSize + fileLength >= maxRemoveDataSize) {
break;
}
// 生成文件复制任务
ReplicateTask replicateTask = new ReplicateTask(
filename, fileLength, sourceDatanode, destDatanode);
destDatanode.addReplicateTask(replicateTask);
destDatanode.addStoredDataSize(fileLength);
// 生成文件删除任务
sourceDatanode.addStoredDataSize(-fileLength);
this.removeReplicaFromDataNode(sourceDatanode.getId(), file);
RemoveReplicaTask removeReplicaTask = new RemoveReplicaTask(
filename, sourceDatanode);
removeReplicaTasks.add(removeReplicaTask);
removedDataSize += fileLength;
}
return removedDataSize;
}
/**
* 从数据节点删除掉一个文件副本元数据
*/
private void removeReplicaFromDataNode(String id, String file) {
try {
rrw.writeLock().lock();
fileMappedByDataNode.get(id).remove(file);
Iterator<DataNodeInfo> replicasIterator = datanodeMappedByFile
.get(file.split("_")[0]).iterator();
while (replicasIterator.hasNext()) {
DataNodeInfo replica = replicasIterator.next();
if (replica.getId().equals(id)) {
replicasIterator.remove();
}
}
} finally {
rrw.writeLock().unlock();
}
}
2.2 文件删除任务
文件删除任务由一个线程定时执行,默认延时24小时后执行,防止出现并发复制和删除问题:
// DataNodeManager.java
/**
* 延迟删除副本的线程
*/
class DelayRemoveReplicaThread extends Thread {
private List<RemoveReplicaTask> removeReplicaTasks;
public DelayRemoveReplicaThread(List<RemoveReplicaTask> removeReplicaTasks) {
this.removeReplicaTasks = removeReplicaTasks;
}
@Override
public void run() {
long start = System.currentTimeMillis();
while (true) {
try {
long now = System.currentTimeMillis();
// 延迟24小时
if (now - start > 24 * 60 * 60 * 1000) {
start = System.currentTimeMillis();
for (RemoveReplicaTask removeReplicaTask : removeReplicaTasks) {
removeReplicaTask.getTargetDataNode().addRemoveReplicaTask(removeReplicaTask);
}
break;
}
Thread.sleep(60 * 1000);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
三、总结
本章,我对分布式文件系统的rebalance机制进行了讲解。Rebalance的核心是根据NameNode中保存的集群元数据信息确认好源datanode和目标datanode,然后创建文件复制任务和文件删除任务,最后复用高可用架构中的心跳下发模式完成rebalance流程。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
