一、ConcurrentSkipListMap简介
1.1 类继承结构
在正式讲ConcurrentSkipListMap之前,我们先来看下ConcurrentSkipListMap的类继承图:

我们知道,一般的Map都是无序的,也就是只能通过键的hash值进行定位。JDK为了实现有序的Map,提供了一个 SortedMap 接口,SortedMap提供了一些根据键范围进行查找的功能,比如返回整个Map中 key最小/大的键、返回某个范围内的子Map视图等等。
为了进一步对有序Map进行增强,JDK又引入了 NavigableMap 接口,该接口进一步扩展了SortedMap的功能,提供了根据指定Key返回最接近项、按升序/降序返回所有键的视图等功能。
同时,也提供了一个基于NavigableMap的实现类—— TreeMap ,TreeMap底层基于红黑树设计,是一种有序的Map。关于TreeMap和NavigableMap,本文不作赘述,读者可以查看Oracle的官方文档:https://docs.oracle.com/javase/8/docs/api。
1.2 ConcurrentSkipListMap的由来
JDK1.6时,为了对高并发环境下的有序Map提供更好的支持,J.U.C新增了一个 ConcurrentNavigableMap 接口,ConcurrentNavigableMap很简单,它同时实现了NavigableMap和ConcurrentMap接口:

ConcurrentNavigableMap 接口提供的功能也和NavigableMap几乎完全一致,很多方法仅仅是返回的类型不同:

J.U.C提供了基于 ConcurrentNavigableMap 接口的一个实现——ConcurrentSkipListMap。ConcurrentSkipListMap可以看成是并发版本的TreeMap,但是和TreeMap不同是,ConcurrentSkipListMap并不是基于红黑树实现的,其底层是一种类似 跳表(Skip List) 的结构。
二、Skip List简介
2.1 什么是Skip List
Skip List (以下简称跳表),是一种类似链表的数据结构,其查询/插入/删除的时间复杂度都是O(logn)。
我们知道,通常意义上的链表是不能支持随机访问的(通过索引快速定位),其查找的时间复杂度是O(n),而数组这一可支持随机访问的数据结构,虽然查找很快,但是插入/删除元素却需要移动插入点后的所有元素,时间复杂度为O(n)。
为了解决这一问题,引入了树结构,树的增删改查效率比较平均,一棵平衡二叉树(AVL)的增删改查效率一般为O(logn),比如工业上常用红黑树作为AVL的一种实现。
但是,AVL的实现一般都比较复杂,插入/删除元素可能涉及对整个树结构的修改,特别是并发环境下,通常需要全局锁来保证AVL的线程安全,于是又出现了一种类似链表的数据结构—— 跳表 。
2.2 Skip List示例
在讲 Skip List 之前,我们先来看下传统的单链表:

上图的单链表中(省去了结点之间的链接),当想查找7、15、46这三个元素时,必须从头指针head开始,遍历整个单链表,其查找复杂度很低,为O(n)。
来看下 Skip List 的数据结构是什么样的:

上图是Skip List一种可能的结构,它分了2层,假设我们要查找 “15” 这个元素,那么整个步骤如下:
- 从头指针 head 开始,找到第一个结点的最上层,发现其指向的下个结点值为8,小于15,则直接从1结点跳到8结点。
- 8结点最上层指向的下一结点值为18,大于15,则从8结点的下一层开始查找。
- 从8结点的最下层一直向后查找,依次经过10、13,最后找到15结点。
上述整个查找路径如下图标黄部分所示:

同理,如果要查找 “46” 这个元素,则整个查找路径如下图标黄部分所示:

上面就是跳跃表的基本思想了,每个结点不仅仅只包含指向下一个结点的指针,可能还包含很多个其它指向后续结点的指针。并且,一个结点本身可以看成是一个链表(自上向下链接)。这样就可以跳过一些不必要的结点,从而加快查找、删除等操作,这其实是一种 “空间换时间” 的算法设计思想。
那么一个结点可以包含多少层呢? 比如,Skip List也可能是下面这种包含3层的结构(在一个3层Skip List中查找元素“46”):

层数是根据一种随机算法得到的,为了不让层数过大,还会有一个最大层数 MAX_LEVEL 限制,随机算法生成的层数不得大于该值。后面讲 ConcurrentSkipListMap 时,我们会具体分析。
以上就是 Skip List 的基本思想了,总结起来,有以下几点:
- 跳表由很多层组成;
- 每一层都是一个有序链表;
- 对于每一层的任意结点,不仅有指向下一个结点的指针,也有指向其下一层的指针。
三、ConcurrentSkipListMap的内部结构
介绍完了跳表,再来看 ConcurrentSkipListMap 的内部结构就容易得多了:

ConcurrentSkipListMap 内部一共定义了3种不同类型的结点,元素的增删改查都从最上层的head指针指向的结点开始:
public class ConcurrentSkipListMap2<K, V> extends AbstractMap<K, V>
implements ConcurrentNavigableMap<K, V>, Cloneable, Serializable {
/**
* 最底层链表的头指针BASE_HEADER
*/
private static final Object BASE_HEADER = new Object();
/**
* 最上层链表的头指针head
*/
private transient volatile HeadIndex<K, V> head;
/* ---------------- 普通结点Node定义 -------------- */
static final class Node<K, V> {
final K key;
volatile Object value;
volatile Node<K, V> next;
// ...
}
/* ---------------- 索引结点Index定义 -------------- */
static class Index<K, V> {
final Node<K, V> node; // node指向最底层链表的Node结点
final Index<K, V> down; // down指向下层Index结点
volatile Index<K, V> right; // right指向右边的Index结点
// ...
}
/* ---------------- 头索引结点HeadIndex -------------- */
static final class HeadIndex<K, V> extends Index<K, V> {
final int level; // 层级
// ...
}
}
我们来看下这3类结点的具体定义。
3.1 结点定义
普通结点:Node
普通结点——Node,也就是 ConcurrentSkipListMap 最底层链表中的结点,保存着实际的键值对,如果单独看底层链,其实就是一个按照Key有序排列的单链表:
static final class Node<K, V> {
final K key;
volatile Object value;
volatile Node<K, V> next;
/**
* 正常结点.
*/
Node(K key, Object value, Node<K, V> next) {
this.key = key;
this.value = value;
this.next = next;
}
/**
* 标记结点.
*/
Node(Node<K, V> next) {
this.key = null;
this.value = this;
this.next = next;
}
/**
* CAS更新结点的value
*/
boolean casValue(Object cmp, Object val) {
return UNSAFE.compareAndSwapObject(this, valueOffset, cmp, val);
}
/**
* CAS更新结点的next
*/
boolean casNext(Node<K, V> cmp, Node<K, V> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
/**
* 判断当前结点是否为[标记结点]
*/
boolean isMarker() {
return value == this;
}
/**
* 判断当前结点是否是最底层链表的头结点
*/
boolean isBaseHeader() {
return value == BASE_HEADER;
}
/**
* 在当前结点后面插入一个标记结点.
*
* @param f 当前结点的后继结点
* @return true 插入成功
*/
boolean appendMarker(Node<K, V> f) {
return casNext(f, new Node<K, V>(f));
}
/**
* 辅助删除结点方法.
*
* @param b 当前结点的前驱结点
* @param f 当前结点的后继结点
*/
void helpDelete(Node<K, V> b, Node<K, V> f) {
/*
* 重新检查一遍结点位置
* 确保b和f分别为当前结点的前驱/后继
*/
if (f == next && this == b.next) {
if (f == null || f.value != f) // f为null或非标记结点
casNext(f, new Node<K, V>(f));
else // 删除当前结点
b.casNext(this, f.next);
}
}
/**
* 返回结点的value值.
*
* @return 标记结点或最底层头结点,直接返回null
*/
V getValidValue() {
Object v = value;
if (v == this || v == BASE_HEADER) // 标记结点或最底层头结点,直接返回null
return null;
V vv = (V) v;
return vv;
}
/**
* 返回当前结点的一个Immutable快照.
*/
AbstractMap.SimpleImmutableEntry<K, V> createSnapshot() {
Object v = value;
if (v == null || v == this || v == BASE_HEADER)
return null;
V vv = (V) v;
return new AbstractMap.SimpleImmutableEntry<K, V>(key, vv);
}
// UNSAFE mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
valueOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("value"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
索引结点:Index
Index 结点是除底层链外,其余各层链表中的非头结点(见示意图中的蓝色结点)。每个Index结点包含3个指针:down、right、node。
down和right指针分别指向下层结点和后继结点,node指针指向其最底部的node结点。
static class Index<K, V> {
final Node<K, V> node; // node指向最底层链表的Node结点
final Index<K, V> down; // down指向下层Index结点
volatile Index<K, V> right; // right指向右边的Index结点
Index(Node<K, V> node, Index<K, V> down, Index<K, V> right) {
this.node = node;
this.down = down;
this.right = right;
}
/**
* CAS更新右边的Index结点
*
* @param cmp 当前结点的右结点
* @param val 希望更新的结点
*/
final boolean casRight(Index<K, V> cmp, Index<K, V> val) {
return UNSAFE.compareAndSwapObject(this, rightOffset, cmp, val);
}
/**
* 判断Node结点是否已经删除.
*/
final boolean indexesDeletedNode() {
return node.value == null;
}
/**
* CAS插入一个右边结点newSucc.
*
* @param succ 当前的后继结点
* @param newSucc 新的后继结点
*/
final boolean link(Index<K, V> succ, Index<K, V> newSucc) {
Node<K, V> n = node;
newSucc.right = succ;
return n.value != null && casRight(succ, newSucc);
}
/**
* 跳过当前结点的后继结点.
*
* @param succ 当前的后继结点
*/
final boolean unlink(Index<K, V> succ) {
return node.value != null && casRight(succ, succ.right);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long rightOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Index.class;
rightOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("right"));
} catch (Exception e) {
throw new Error(e);
}
}
}
头索引结点:HeadIndex
HeadIndex 结点是各层链表的头结点,它是Index类的子类,唯一的区别是增加了一个level字段,用于表示当前链表的级别,越往上层,level值越大。
static final class HeadIndex<K, V> extends Index<K, V> {
final int level; // 层级
HeadIndex(Node<K, V> node, Index<K, V> down, Index<K, V> right, int level) {
super(node, down, right);
this.level = level;
}
}
3.2 构造器定义和初始化
ConcurrentSkipListMap 一共定义了4种构造器:
空构造器
/**
* 构造一个新的空Map.
*/
public ConcurrentSkipListMap() {
this.comparator = null;
initialize();
}
指定比较器的构造器
/**
* 构造一个新的空Map.
* 并指定比较器.
*/
public ConcurrentSkipListMap(Comparator<? super K> comparator) {
this.comparator = comparator;
initialize();
}
从给定Map构建的构造器
/**
* 从已给定的Map构造一个新Map.
*/
public ConcurrentSkipListMap(Map<? extends K, ? extends V> m) {
this.comparator = null;
initialize();
putAll(m);
}
从给定SortedMap构建的构造器
/**
* 从已给定的SortedMap构造一个新Map.
* 并且Key的顺序与原来保持一致.
*/
public ConcurrentSkipListMap(SortedMap<K, ? extends V> m) {
this.comparator = m.comparator();
initialize();
buildFromSorted(m);
}
注:ConcurrentSkipListMap会基于比较器——Comparator ,来进行键Key的比较,如果构造时未指定Comparator ,那么就会按照Key的自然顺序进行比较,所谓Key的自然顺序是指key实现Comparable接口。
上述所有构造器都调用了 initialize 方法:
private void initialize() {
keySet = null;
entrySet = null;
values = null;
descendingMap = null;
head = new HeadIndex<K, V>(new Node<K, V>(null, BASE_HEADER, null),null, null, 1);
}
initialize 方法将一些字段置初始化null,然后将head指针指向新创建的 HeadIndex 结点。初始化完成后,ConcurrentSkipListMap的结构如下:
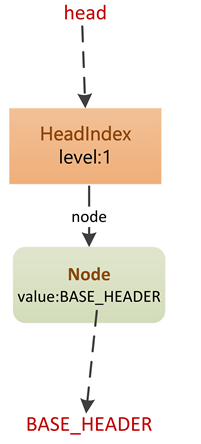
其中, head 和 BASE_HEADER 都是ConcurrentSkipListMap的字段:
/**
* 最底层链表的头指针BASE_HEADER
*/
private static final Object BASE_HEADER = new Object();
/**
* 最上层链表的头指针head
*/
private transient volatile HeadIndex<K, V> head;
四、ConcurrentSkipListMap的核心操作
4.1 put操作
put 操作本身很简单,需要注意的是ConcurrentSkipListMap在插入键值对时,Key和Value都不能为null:
/**
* 插入键值对.
*
* @param key 键
* @param value 值
* @return 如果key存在,返回旧value值;否则返回null
*/
public V put(K key, V value) {
if (value == null) // ConcurrentSkipListMap的Value不能为null
throw new NullPointerException();
return doPut(key, value, false);
}
上述方法内部调用了 doPut 来做实际的插入操作:
/**
* 插入键值对.
*
* @param onlyIfAbsent true: 仅当Key不存在时才进行插入
*/
private V doPut(K key, V value, boolean onlyIfAbsent) {
Node<K, V> z; // z指向待添加的Node结点
if (key == null) // ConcurrentSkipListMap的Key不能为null
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer:
for (; ; ) {
// b是“是小于且最接近给定key”的Node结点(或底层链表头结点)
for (Node<K, V> b = findPredecessor(key, cmp), n = b.next; ; ) {
if (n != null) { // b存在后驱结点: b -> n -> f
Object v;
int c;
Node<K, V> f = n.next; // f指向b的后驱的后驱
if (n != b.next) // 存在并发修改,放弃并重试
break;
if ((v = n.value) == null) { // n为标记删除结点
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n) // b为标记删除结点
break;
if ((c = cpr(cmp, key, n.key)) > 0) { // 向后遍历,找到第一个大于key的结点
b = n;
n = f;
continue;
}
if (c == 0) { // 存在Key相同的结点
if (onlyIfAbsent || n.casValue(v, value)) {
V vv = (V) v;
return vv;
}
break; // CAS更新失败,则重试
}
}
z = new Node<K, V>(key, value, n);
if (!b.casNext(n, z)) // 尝试插入z结点: b -> z -> n
break; // CAS插入失败,则重试
break outer; // 跳出最外层循环
}
}
int rnd = ThreadLocalRandom.nextSecondarySeed(); // 生成一个随机数种子
if ((rnd & 0x80000001) == 0) { // 为true表示需要增加层级
/**
* 以下方法用于创建新层级
*/
int level = 1, max;
while (((rnd >>>= 1) & 1) != 0) // level表示新的层级,通过下面这个while循环可以确认新的层级数
++level;
Index<K, V> idx = null;
HeadIndex<K, V> h = head;
if (level <= (max = h.level)) { // CASE1: 新层级level没有超过最大层级head.level(head指针指向最高层)
// 以“头插法”创建level个Index结点,idx最终指向最高层的Index结点
for (int i = 1; i <= level; ++i)
idx = new Index<K, V>(z, idx, null);
}
else { // CASE2: 新层级level超过了最大层级head.level
level = max + 1; // 重置level为最大层级+1
// 生成一个Index结点数组,idxs[0]不会使用
Index<K, V>[] idxs = (Index<K, V>[]) new Index<?, ?>[level + 1];
for (int i = 1; i <= level; ++i)
idxs[i] = idx = new Index<K, V>(z, idx, null);
// 生成新的HeadIndex结点
for (; ; ) {
h = head;
int oldLevel = h.level; // 原最大层级
if (level <= oldLevel)
break;
HeadIndex<K, V> newh = h;
Node<K, V> oldbase = h.node; // oldbase指向最底层链表的头结点
for (int j = oldLevel + 1; j <= level; ++j)
newh = new HeadIndex<K, V>(oldbase, newh, idxs[j], j);
if (casHead(h, newh)) {
h = newh;
idx = idxs[level = oldLevel];
break;
}
}
}
/**
* 以下方法用于链接新层级的各个HeadIndex和Index结点
*/
splice:
for (int insertionLevel = level; ; ) { // 此时level为oldLevel,即原最大层级
int j = h.level;
for (Index<K, V> q = h, r = q.right, t = idx; ; ) {
if (q == null || t == null)
break splice;
if (r != null) {
Node<K, V> n = r.node;
int c = cpr(cmp, key, n.key);
if (n.value == null) {
if (!q.unlink(r))
break;
r = q.right;
continue;
}
if (c > 0) {
q = r;
r = r.right;
continue;
}
}
if (j == insertionLevel) {
if (!q.link(r, t)) // 在q和r之间插入t,即从 q -> r 变成 q -> t -> r
break;
if (t.node.value == null) {
findNode(key);
break splice;
}
if (--insertionLevel == 0)
break splice;
}
if (--j >= insertionLevel && j < level)
t = t.down;
q = q.down;
r = q.right;
}
}
}
return null;
}
我们先不急着看 doPut 方法,而是看下其内部的findPredecessor方法,findPredecessor用于查找 “小于且最接近给定key”的Node结点,并且这个Node结点必须有上层结点 :
/**
* 返回“小于且最接近给定key”的数据结点.
* 如果不存在这样的数据结点,则返回底层链表的头结点.
*
* @param key 待查找的键
*/
private Node<K, V> findPredecessor(Object key, Comparator<? super K> cmp) {
if (key == null)
throw new NullPointerException();
/**
* 从最上层开始,往右下方向查找
*/
for (; ; ) {
for (Index<K, V> q = head, r = q.right, d; ; ) { // 从最顶层的head结点开始查找
if (r != null) { // 存在右结点
Node<K, V> n = r.node;
K k = n.key;
if (n.value == null) { // 处理结点”懒删除“的情况
if (!q.unlink(r))
break;
r = q.right;
continue;
}
if (cpr(cmp, key, k) > 0) { // key大于k,继续向右查找
q = r;
r = r.right;
continue;
}
}
//已经到了level1的层
if ((d = q.down) == null) // 不存在下结点,说明q已经是level1链表中的结点了
return q.node; // 直接返回对应的Node结点
// 转到下一层,继续查找(level-1层)
q = d;
r = d.right;
}
}
}
看代码不太直观,我们还是看下面这个图:

上图中,假设要查找的Key为72,则步骤如下:
- 从最上方head指向的结点开始,比较①号标红的Index结点的key值,发现3小于72,则继续向右;
- 比较②号标红的Index结点的key值,发现62小于72,则继续向右
- 由于此时右边是null,则转而向下,一直到⑥号标红结点;
- 由于⑥号标红结点的down字段为空(不能再往下了,已经是level1最低层了),则直接返回它的node字段指向的结点,即⑧号结点。
注意:如果我们要查找key为59的Node结点,返回的不是Key为45的结点,而是key为23的结点。读者可以自己在纸上比划下。
回到 doPut 方法,假设现在待插入的Key为3,则当执行完下面这段代码后,ConcurrentSkipListMap的结构如下:

/**
* 插入键值对.
*
* @param onlyIfAbsent true: 仅当Key不存在时才进行插入
*/
private V doPut(K key, V value, boolean onlyIfAbsent) {
Node<K, V> z; // z指向待添加的Node结点
if (key == null) // ConcurrentSkipListMap的Key不能为null
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer:
for (; ; ) {
// b是“是小于且最接近给定key”的Node结点(或底层链表头结点)
for (Node<K, V> b = findPredecessor(key, cmp), n = b.next; ; ) {
if (n != null) { // b存在后驱结点: b -> n -> f
Object v;
int c;
Node<K, V> f = n.next; // f指向b的后驱的后驱
if (n != b.next) // 存在并发修改,放弃并重试
break;
if ((v = n.value) == null) { // n为标记删除结点
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n) // b为标记删除结点
break;
if ((c = cpr(cmp, key, n.key)) > 0) { // 向后遍历,找到第一个大于key的结点
b = n;
n = f;
continue;
}
if (c == 0) { // 存在Key相同的结点
if (onlyIfAbsent || n.casValue(v, value)) {
V vv = (V) v;
return vv;
}
break; // CAS更新失败,则重试
}
}
z = new Node<K, V>(key, value, n);
if (!b.casNext(n, z)) // 尝试插入z结点: b -> z -> n
break; // CAS插入失败,则重试
break outer; // 跳出最外层循环
}
// ...
}
}
上面是 doPut 中的第一个循环,作用就是找到底层链表的插入点,然后插入结点(在查找过程中可能会删除一些已标记的删除结点)。
插入完成后,doPut方法并没结束,我们之前说过 ConcurrentSkipListMap 的分层数是通过一个随机数生成算法来确定,doPut的后半段,就是这个作用:判断是否需要增加层级,如果需要就在各层级中插入对应的Index结点。
/**
* 插入键值对.
*
* @param onlyIfAbsent true: 仅当Key不存在时才进行插入
*/
private V doPut(K key, V value, boolean onlyIfAbsent) {
// ...
int rnd = ThreadLocalRandom.nextSecondarySeed(); // 生成一个随机数种子
if ((rnd & 0x80000001) == 0) { // 为true表示需要增加层级
/**
* 以下方法用于创建新层级
*/
int level = 1, max;
while (((rnd >>>= 1) & 1) != 0) // level表示新的层级,通过下面这个while循环可以确认新的层级数
++level;
Index<K, V> idx = null;
HeadIndex<K, V> h = head;
if (level <= (max = h.level)) { // CASE1: 新层级level没有超过最大层级head.level(head指针指向最高层)
// 以“头插法”创建level个Index结点,idx最终指向最高层的Index结点
for (int i = 1; i <= level; ++i)
idx = new Index<K, V>(z, idx, null);
}
else { // CASE2: 新层级level超过了最大层级head.level
level = max + 1; // 重置level为最大层级+1
// 生成一个Index结点数组,idxs[0]不会使用
Index<K, V>[] idxs = (Index<K, V>[]) new Index<?, ?>[level + 1];
for (int i = 1; i <= level; ++i)
idxs[i] = idx = new Index<K, V>(z, idx, null);
// 生成新的HeadIndex结点
for (; ; ) {
h = head;
int oldLevel = h.level; // 原最大层级
if (level <= oldLevel)
break;
HeadIndex<K, V> newh = h;
Node<K, V> oldbase = h.node; // oldbase指向最底层链表的头结点
for (int j = oldLevel + 1; j <= level; ++j)
newh = new HeadIndex<K, V>(oldbase, newh, idxs[j], j);
if (casHead(h, newh)) {
h = newh;
idx = idxs[level = oldLevel];
break;
}
}
}
/**
* 以下方法用于链接新层级的各个HeadIndex和Index结点
*/
splice:
for (int insertionLevel = level; ; ) { // 此时level为oldLevel,即原最大层级
int j = h.level;
for (Index<K, V> q = h, r = q.right, t = idx; ; ) {
if (q == null || t == null)
break splice;
if (r != null) {
Node<K, V> n = r.node;
int c = cpr(cmp, key, n.key);
if (n.value == null) {
if (!q.unlink(r))
break;
r = q.right;
continue;
}
if (c > 0) {
q = r;
r = r.right;
continue;
}
}
if (j == insertionLevel) {
if (!q.link(r, t)) // 在q和r之间插入t,即从 q -> r 变成 q -> t -> r
break;
if (t.node.value == null) {
findNode(key);
break splice;
}
if (--insertionLevel == 0)
break splice;
}
if (--j >= insertionLevel && j < level)
t = t.down;
q = q.down;
r = q.right;
}
}
}
return null;
}
最终ConcurrentSkipListMap的结构如下所示:

4.2 remove操作
ConcurrentSkipListMap 在删除键值对时,不会立即执行删除,而是通过引入 “标记结点” ,以 “懒删除” 的方式进行,以提高并发效率。
public V remove(Object key) {
return doRemove(key, null);
}
remove 方法很简单,内部调用了 doRemove 方法:
final V doRemove(Object key, Object value) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer:
for (; ; ) {
// b指向“小于且最接近给定key”的Node结点(或底层链表头结点)
for (Node<K, V> b = findPredecessor(key, cmp), n = b.next; ; ) { // b -> n
Object v;
int c;
if (n == null)
break outer;
Node<K, V> f = n.next; // b -> n -> f
if (n != b.next) // 一致性判断
break;
if ((v = n.value) == null) { // n is deleted
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n) // b is deleted
break;
if ((c = cpr(cmp, key, n.key)) < 0)
break outer;
if (c > 0) {
b = n;
n = f;
continue;
}
// 此时n指向查到的结点
if (value != null && !value.equals(v))
break outer;
if (!n.casValue(v, null)) // 更新查找到的结点的value为null
break;
// 在n和f之间添加标记结点,并将b直接指向f
if (!n.appendMarker(f) || !b.casNext(n, f)) // n -> marker -> f
findNode(key); // retry via findNode
else {
findPredecessor(key, cmp); // 删除Index结点
if (head.right == null) // 减少层级
tryReduceLevel();
}
V vv = (V) v;
return vv;
}
}
return null;
}
还是通过示例来理解上述代码,假设现在要删除Key==23的结点,删除前ConcurrentSkipListMap的结构如下:

doRemove 方法首先会找到待删除的结点,在它和后继结点之间插入一个 value为null的标记结点 (如下图中的绿色结点),然后改变其前驱结点的指向:

最后,doRemove会重新调用一遍 findPredecessor 方法,解除被删除结点上的Index结点之间的引用:

这样Key==23的结点其实就被孤立,再后续查找或插入过程中,会被完全清除或被GC回收。
4.3 get操作
最后,我们来看下ConcurrentSkipListMap的查找操作——get方法。
public V get(Object key) {
return doGet(key);
}
内部调用了 doGet 方法:
private V doGet(Object key) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer:
for (; ; ) {
// b指向“小于且最接近给定key”的Node结点(或底层链表头结点)
for (Node<K, V> b = findPredecessor(key, cmp), n = b.next; ; ) {
Object v;
int c;
if (n == null)
break outer;
Node<K, V> f = n.next; // b -> n -> f
if (n != b.next)
break;
if ((v = n.value) == null) { // n is deleted
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n) // b is deleted
break;
if ((c = cpr(cmp, key, n.key)) == 0) {
V vv = (V) v;
return vv;
}
if (c < 0)
break outer;
b = n;
n = f;
}
}
return null;
}
doGet方法非常简单:
首先找到“小于且最接近给定key”的Node结点,然后用了三个指针:b -> n -> f,
n用于定位最终查找的Key,然后顺着链表一步步向下查,比如查找KEY==45,则最终三个指针的位置如下:

Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
