5. 路由模块
5.5 AST语义解析路由
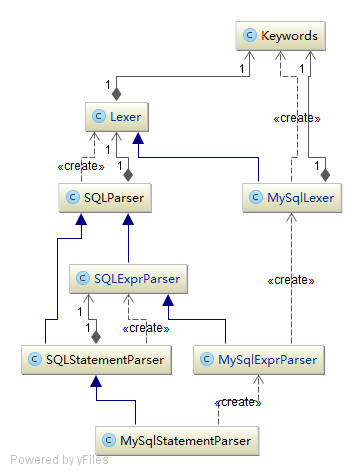
DruidParser结构:
基本使用解析代码:
//sql是一组SQL语句
MySqlStatementParser parser = new MySqlStatementParser(sql);
//获取每个语句粗粒度的parse结果
List<SQLStatement> statementList = parser.parseStatementList();
//获取每个语句更细粒度的parse结果
for(SQLStatement statement:statementList){
MySqlSchemaStatVisitor visitor = new MySqlSchemaStatVisitor();
statemen.accept(visitor);
}
我们来看下一个例句解析出来的结果是啥:
例句:
select concat(s.id,'_',s.name),s.value,t.name from student s,teacher t where s.value>60 and s.teacher=t.name order by s.value
解析代码:
MySqlStatementParser parser = new MySqlStatementParser("selectconcat(s.id,'_',s.name),s.value,t.name from student s,teacher t where s.value>60 and s.teacher=t.name order by s.value");
List<SQLStatement> statementList = parser.parseStatementList();
SQLStatement stmt = statementList.get(0);
MySqlSchemaStatVisitor visitor = new MySqlSchemaStatVisitor();
stmt.accept(visitor);
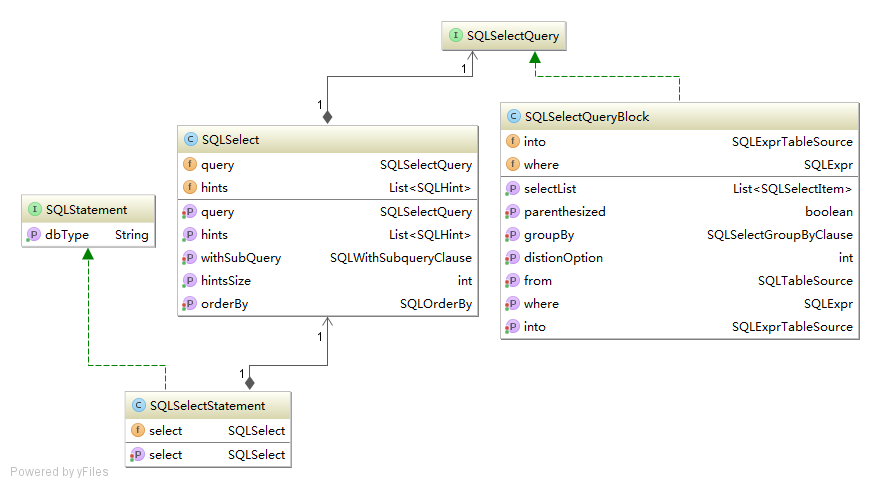
首先第一步粗粒度解析,解析出来的是一个SQLStatement,对于本条语句实际实现和涉及到的主要类是:
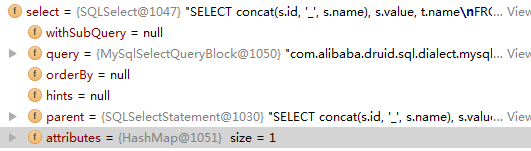
这里解释下,对于本语句,具体实现为SQLSelectStatement。SQLSelectStatement里面包含一个SQLSelect类。由于我们用的是MySqlStatementParser解析,所以dbType为mysql。parent为空,因为这句SQL的select是AST语意树的根节点。attributes为空,因为没有设置一些特殊参数。

SQLSelect类由如下几部分组成:
- withSubQuery:对于MySQL无意义
- query:这里对应的实现是SQLSelectQueryBlock
- orderBy:对于MySQL无意义
- hints:对于MySQL无意义
- parent: 指向刚刚的SQLSelectStatement实例
- attributes:一些特殊参数
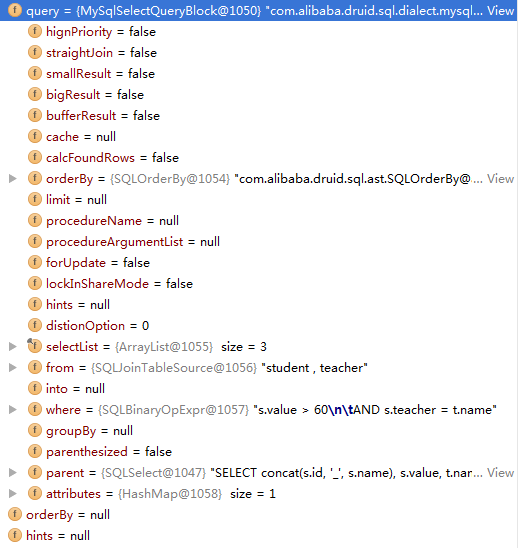
然后我们看下query对应的MySqlSelectQueryBlock,里面的属性比较一目了然,这里就不一一详细解释:
首先我们的语句里面,有select列,有目标表,有where条件,有order by。这里对应的都有。
select列:
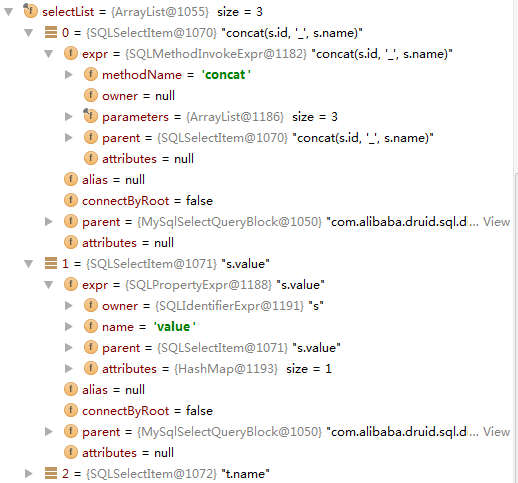
注意,这里我们可以看到,解析出来的并没有考虑别名。
目标表:

where条件:
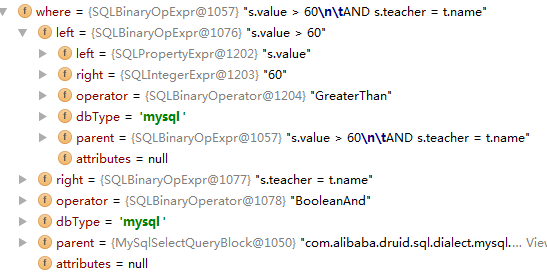
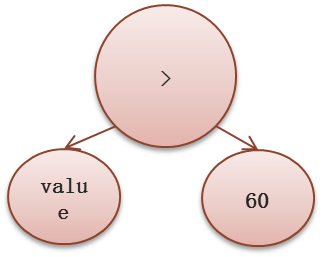
注意,这里where条件可以看出是个这样的树结构:
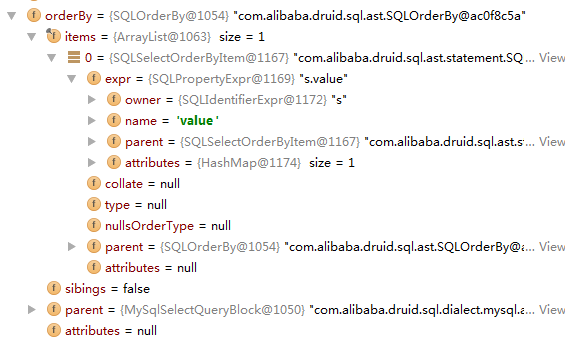
order by:
然后,我们看下,经过visitor之后,解析出了啥:
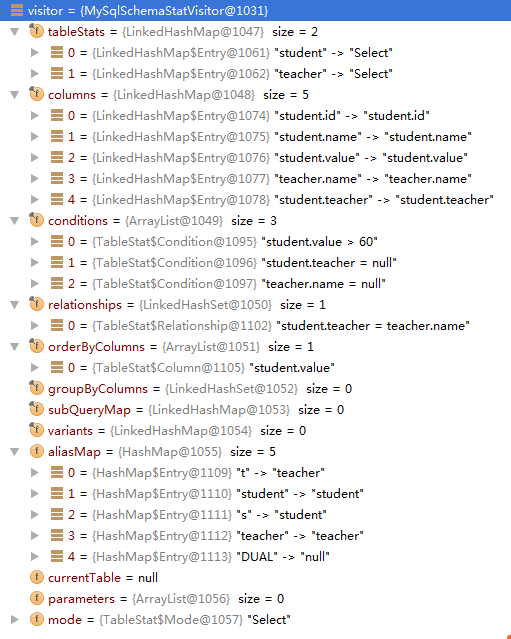
首先一个明显的区别就是将别名解析出来,之后还有一些对于模式结构的解析。
在MyCat中,我们按照需要,进行不同程度的解析。
回归正题,来看routeNormalSqlWithAST()方法
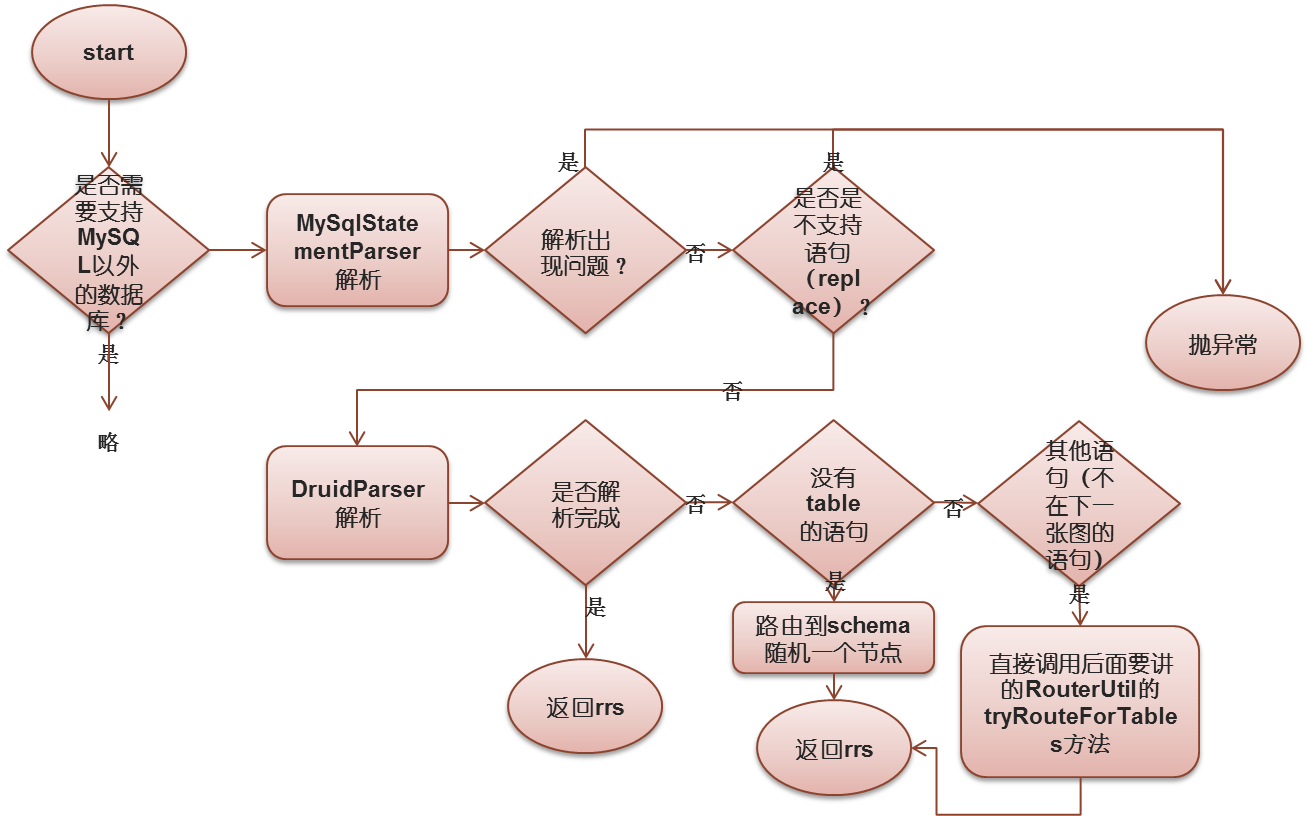
具体的源代码这里先不放。我们具体分析DruidParser解析步骤,这里是MyCat内自己实现的一套继承于源DruidParser的一些类。
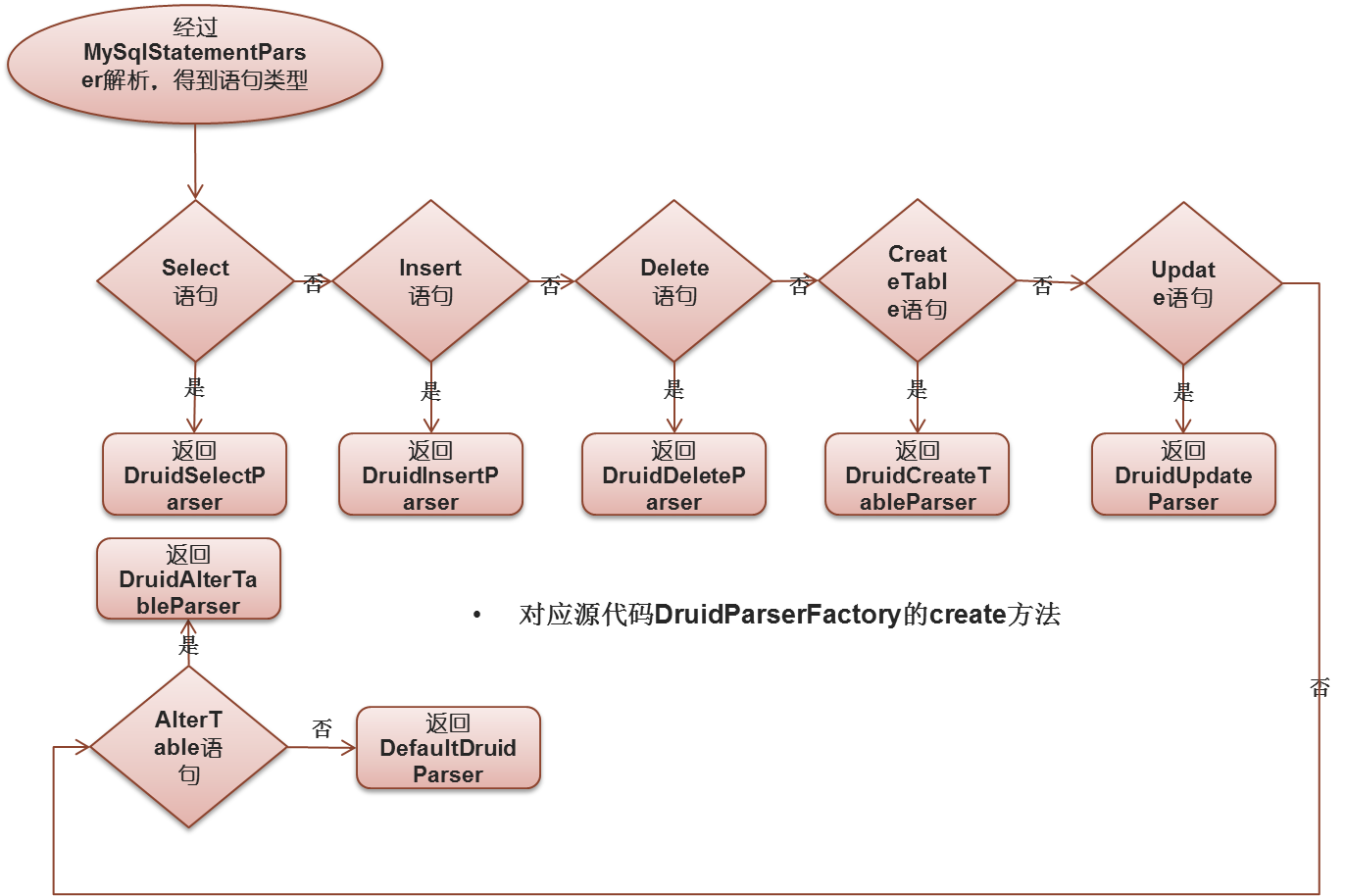
以DruidSelectParser为例 ,说明接下来的DruidParser解析步骤:
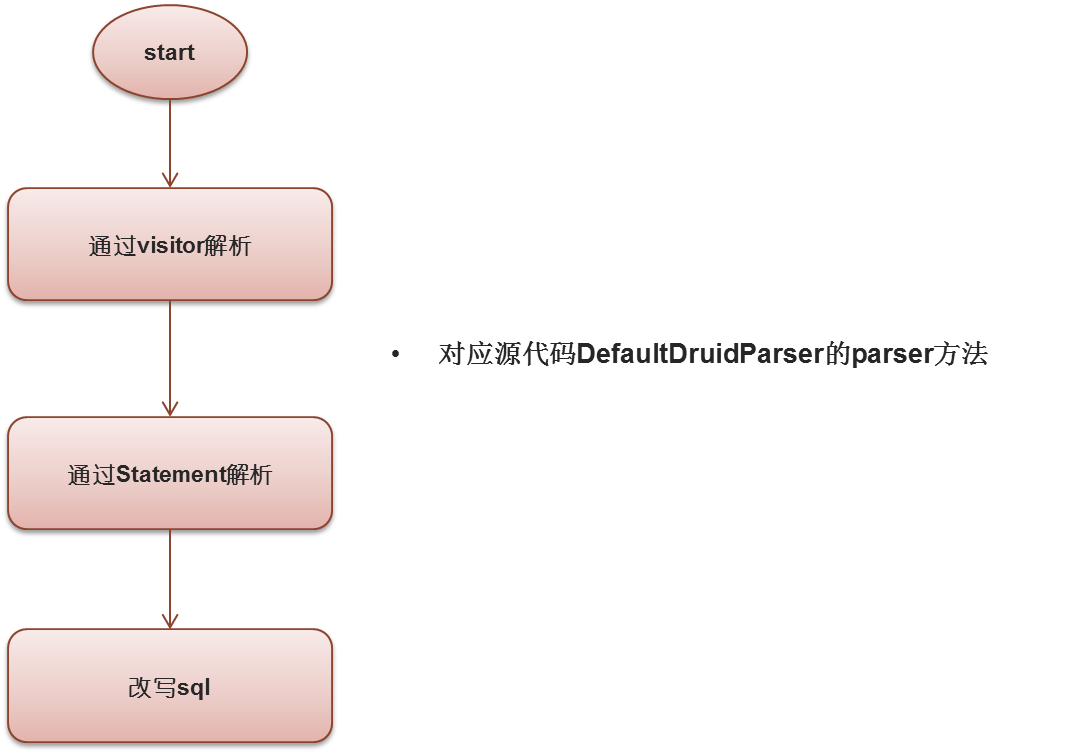
visitor解析操作:
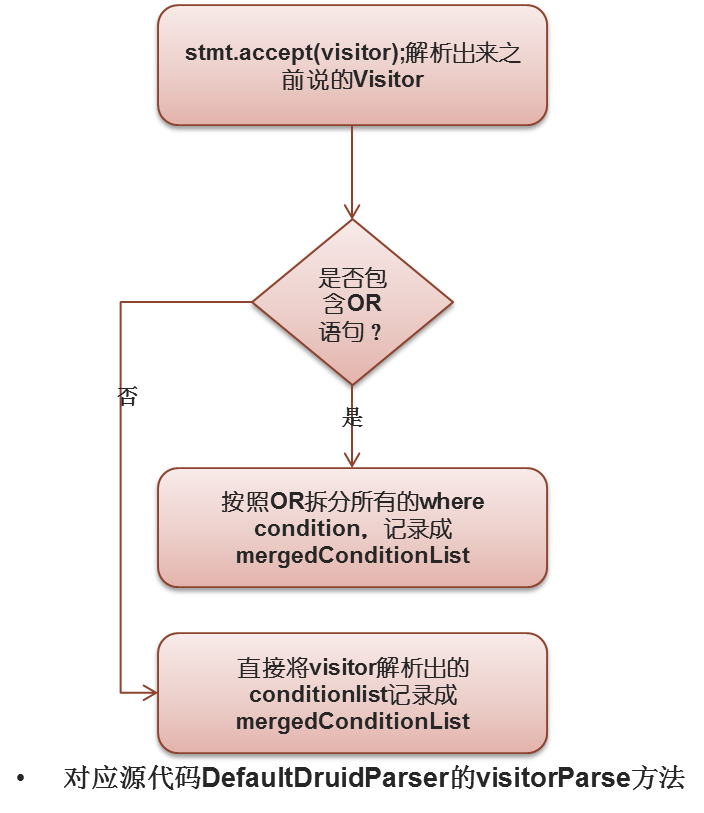
注意mergedConditionList包含所有condition,包括子查询的
需要考虑or语句必定为真的路由:权威指南是这么说的,其实后来没必要了,druidparser已经自动过滤了or为永远真的条件
select * from hotnews where id =1 or 1 = 1;
转换为:
select * from hotnews
现在主要要做的就是将OR语句拆成OR块。为什么要根据OR拆呢?AND运算优先级更高,OR运算优先级低。然后,还有OR是最影响分片的
select * from hotnews where id =1 and score > 60 or title = 'a';
这句话需要路由到后台每个分片上,而不是id=1的
接下来:
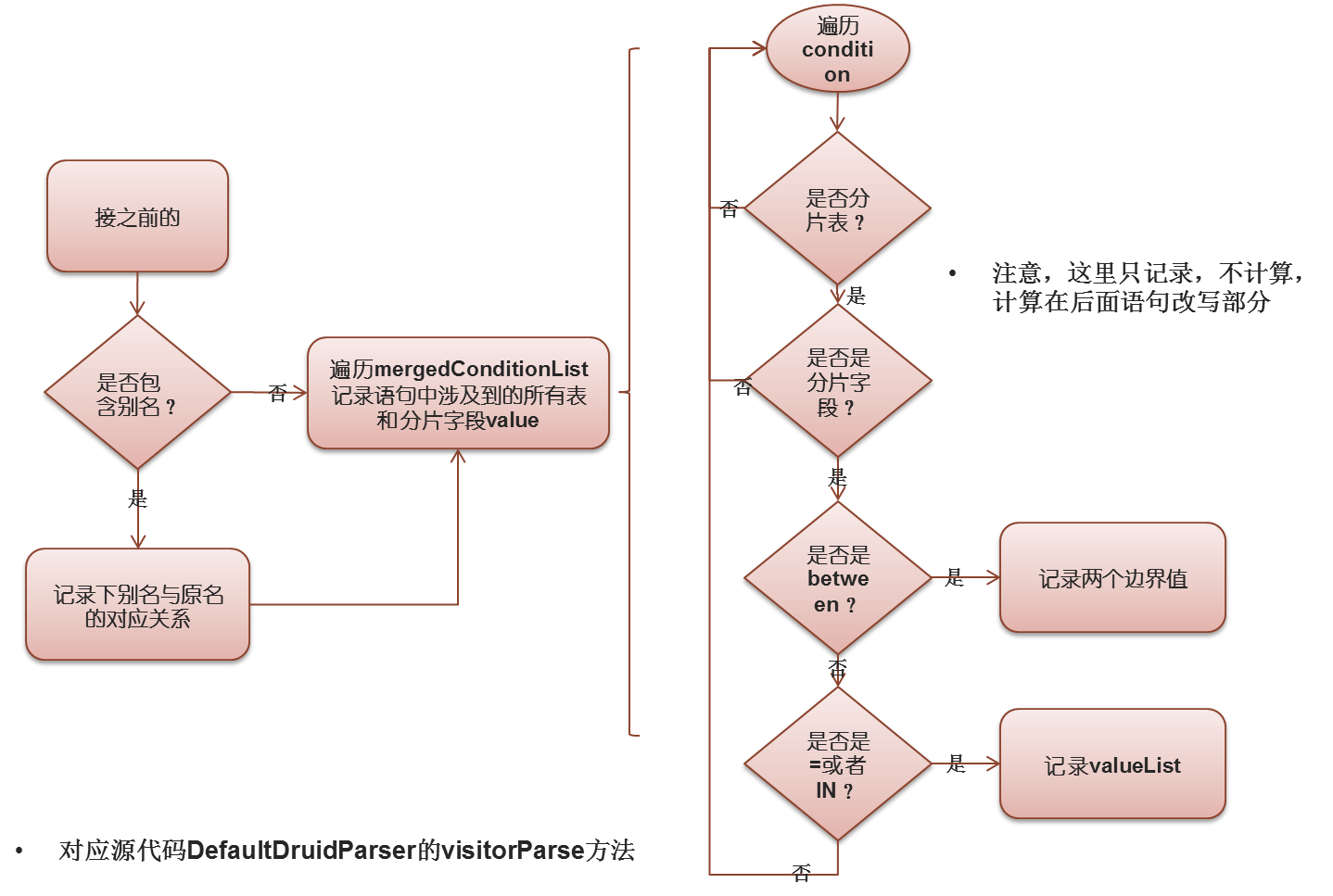
主要是将mergedConditionList中需要做路由计算的元素提取并记录下来。
下一步是Statement解析操作:
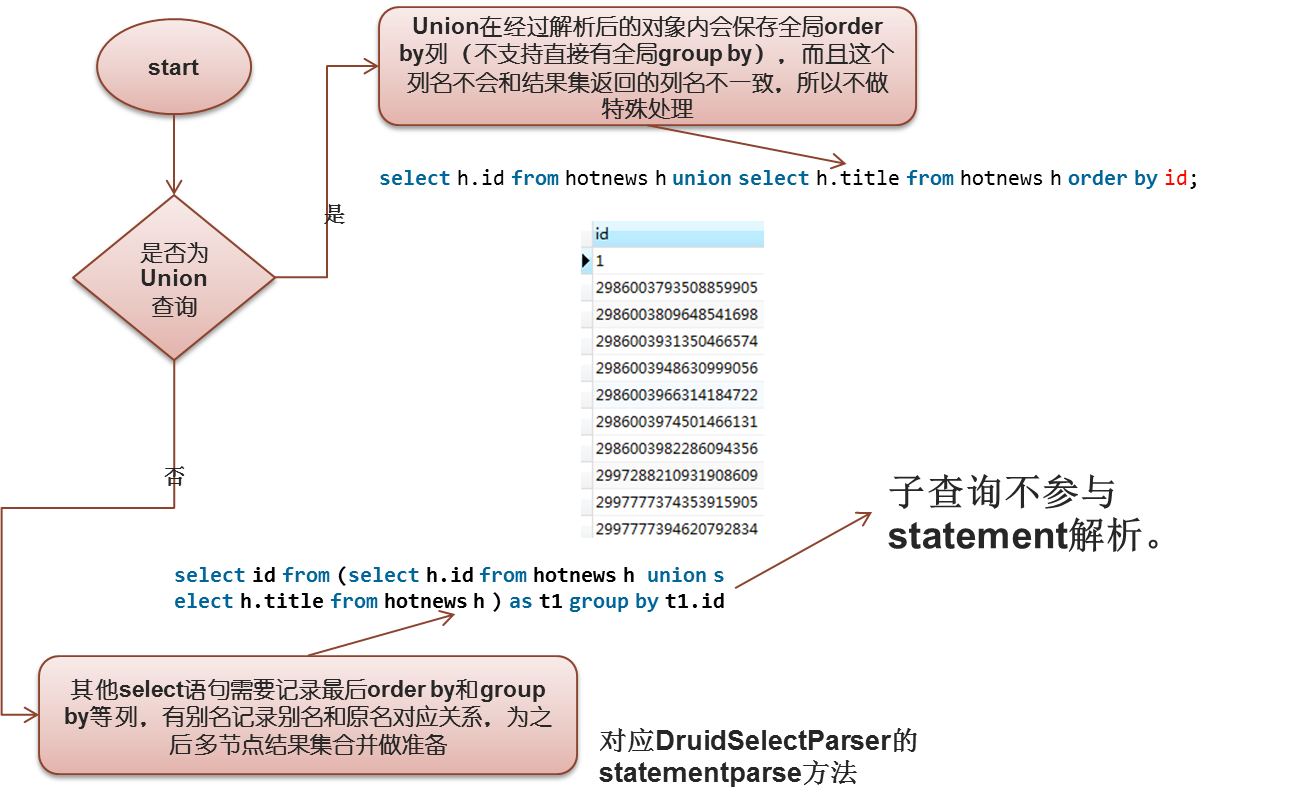
Statement解析主要做别名记录(主要针对order by,group by还有一些聚合函数。这样在之后的结果集合并有理可循)
最后一步是改写SQL操作:
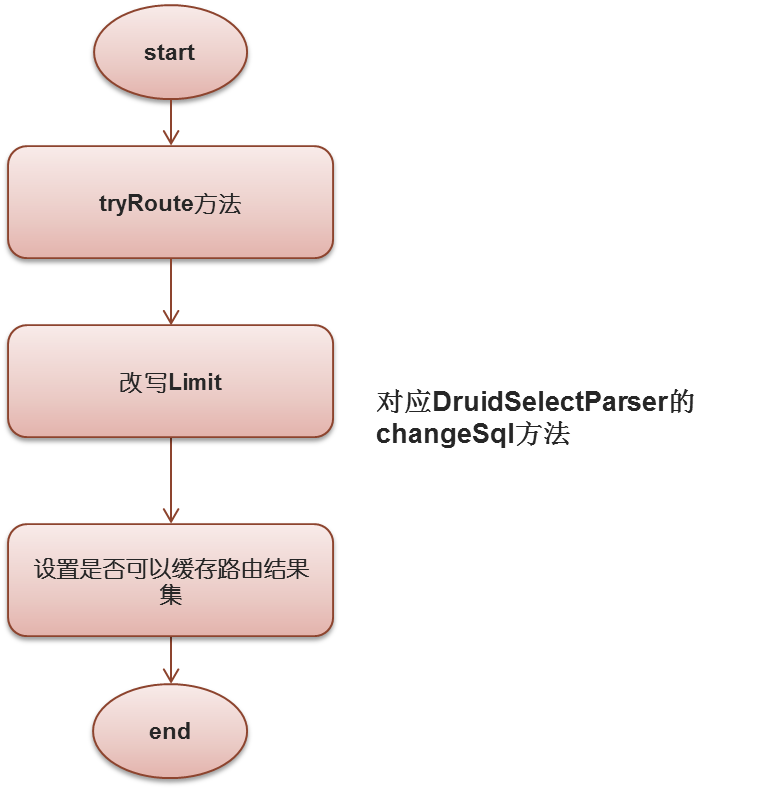
首先是tryRoute方法:
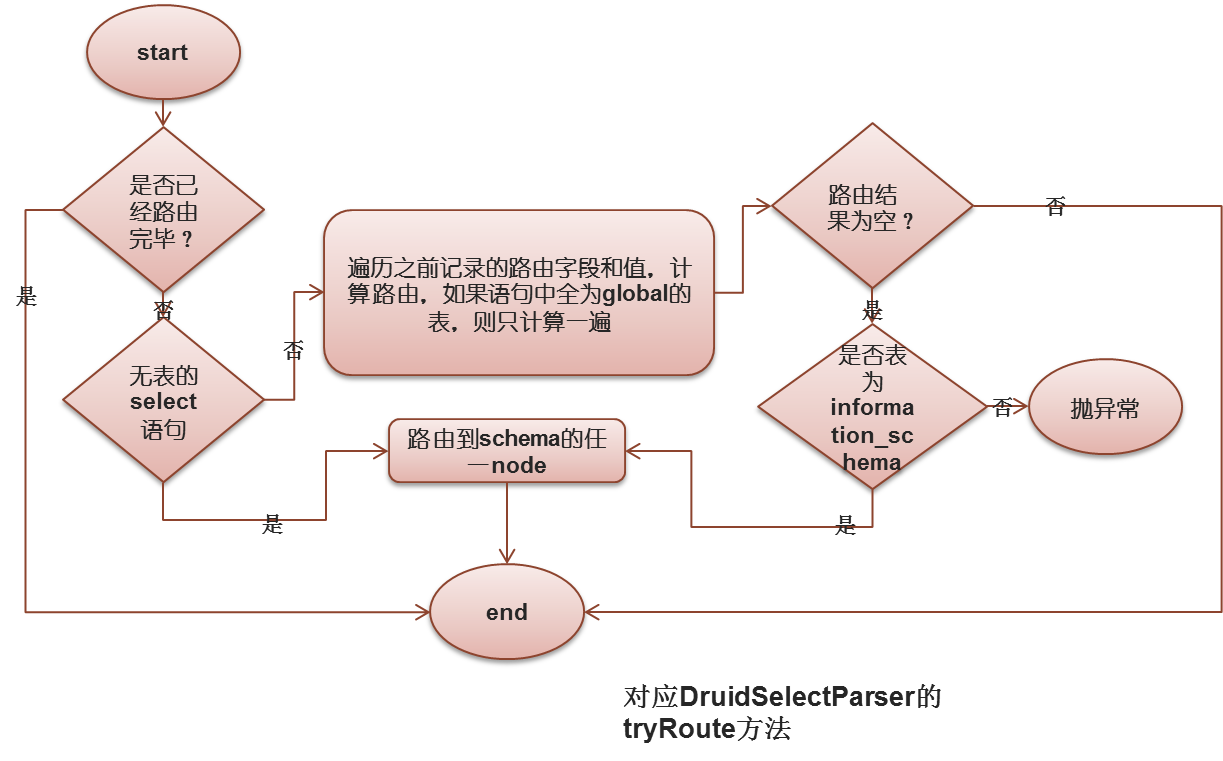
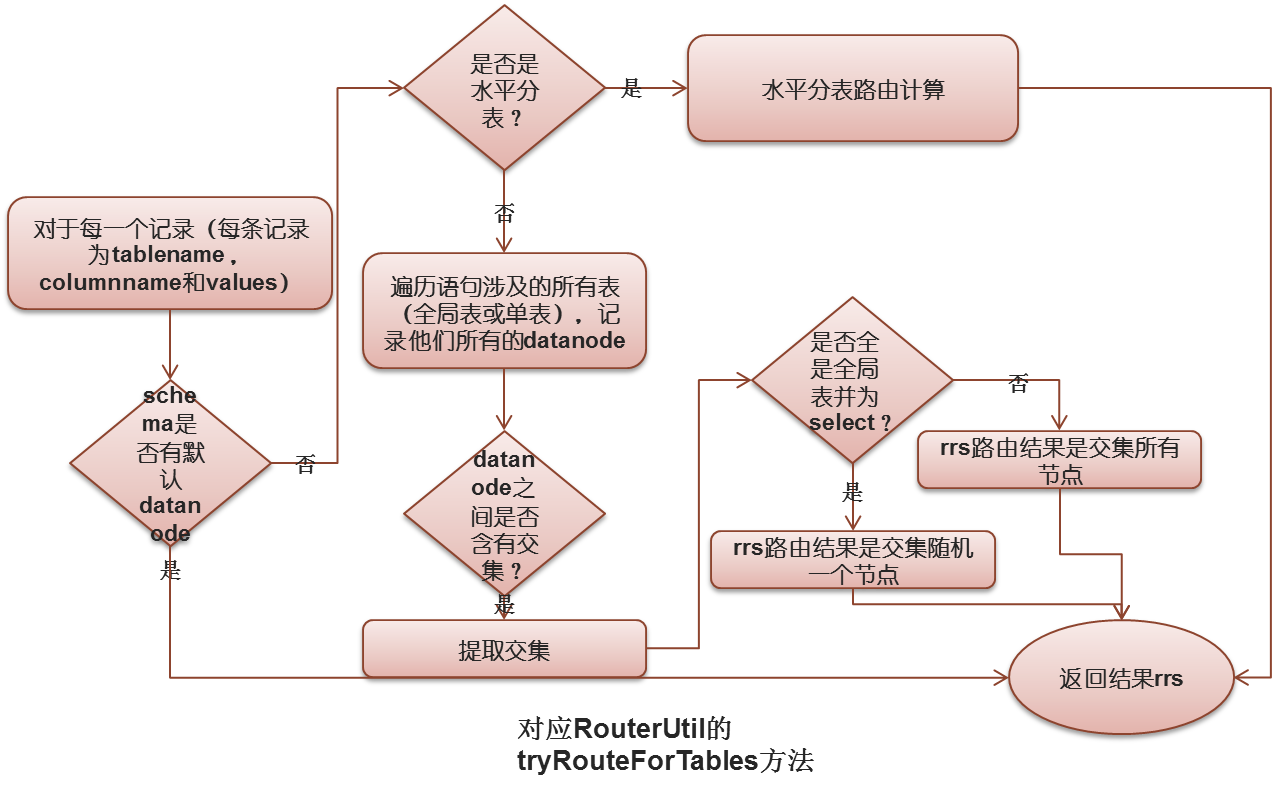
遍历之前记录的路由字段和值,计算路由,如果语句中全为global的表,则只计算一遍,这个具体步骤是:
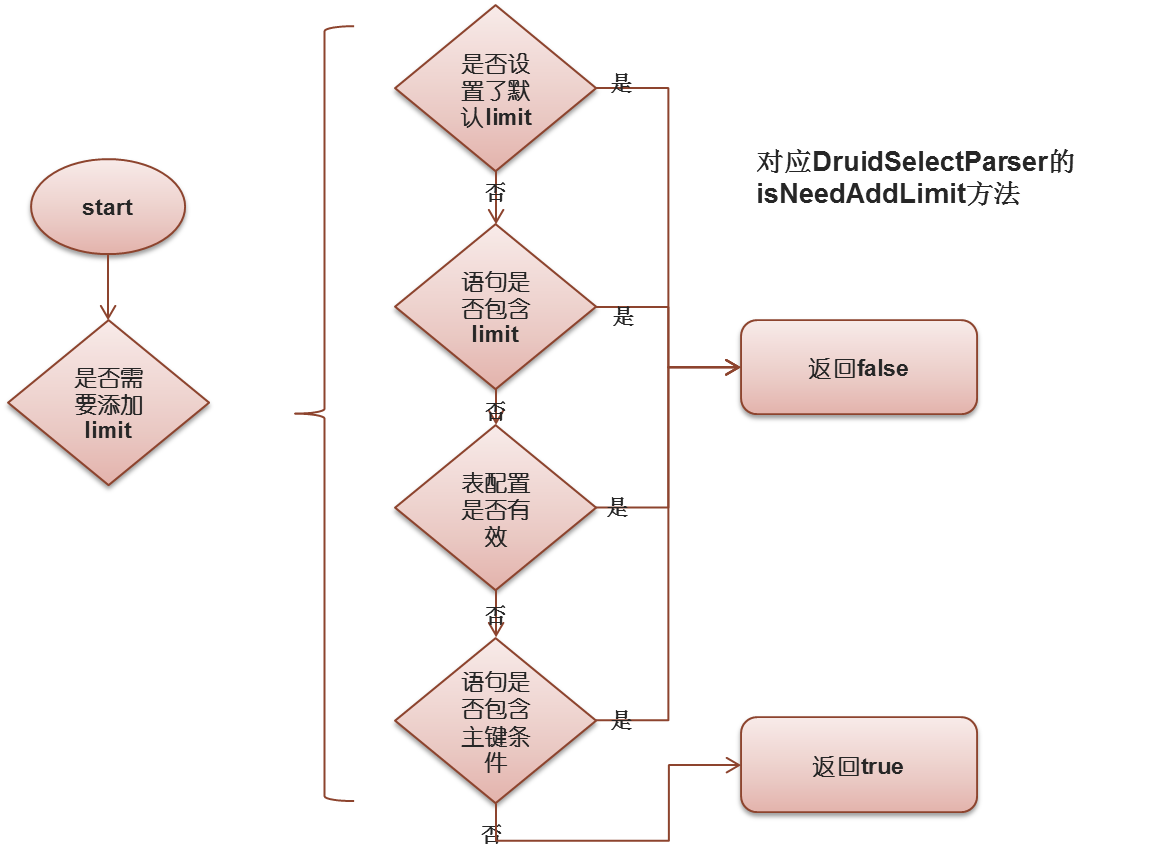
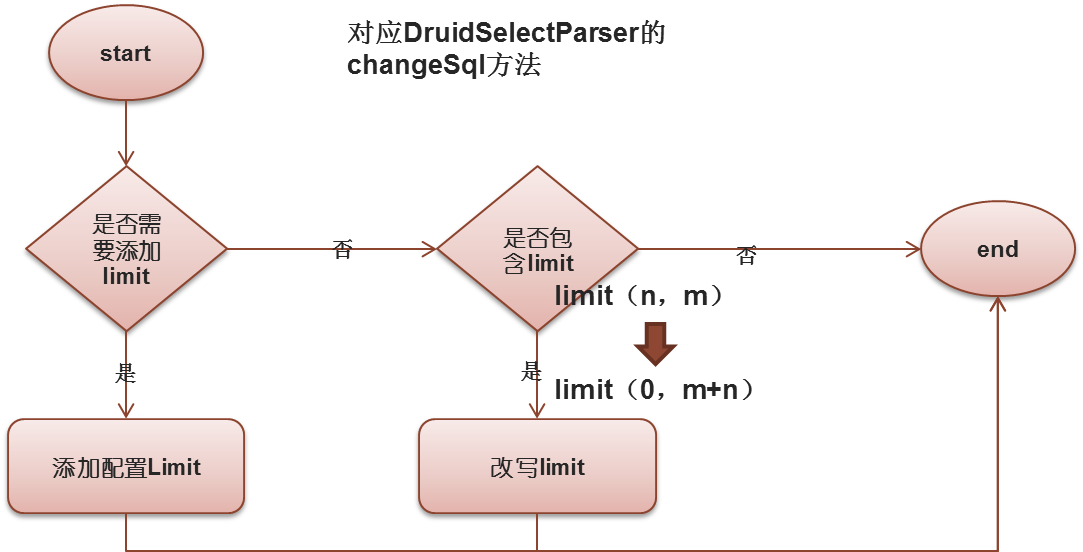
改写limit步骤:
最后是判断是否需要缓存:
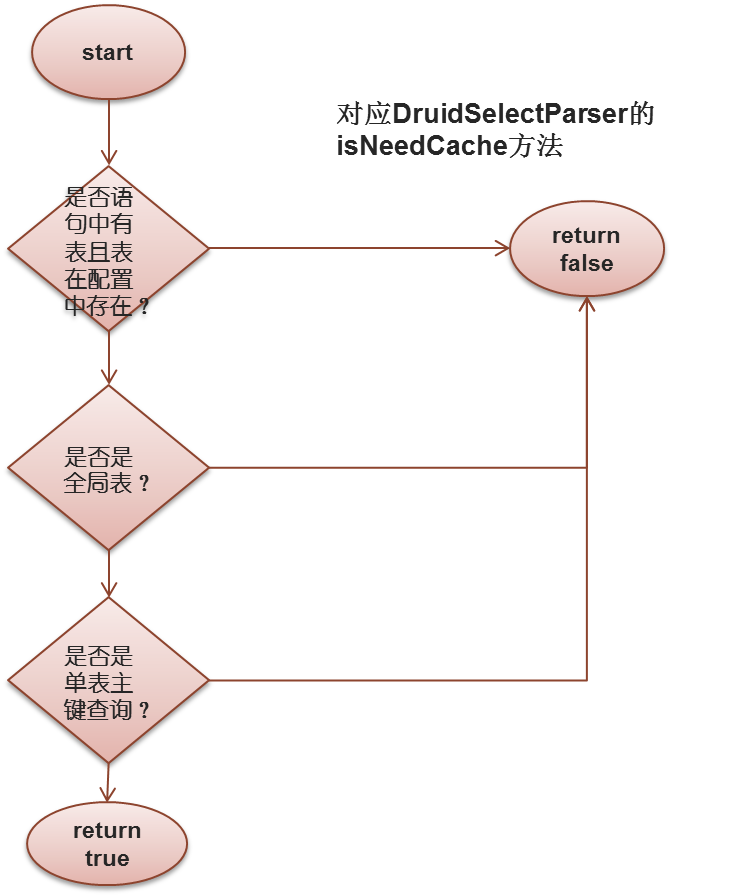
至此,路由模块结束
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
