前面我们学习了linux内核中对于物理上连续的分配方式,采用伙伴系统和slub分配器分配内存,但是我们知道物理上连续的映射是最好的分配方式,但并不总能成功地使用。在分配一大块内存时,可能竭尽全力也无法找到连续的内存块。针对这种情况内核提供了一种申请一片连续的虚拟地址空间,但不保证物理空间连续,也就是vmalloc接口。
- vmalloc的工作方式类似于kmalloc,只不过前者分配的内存虚拟地址连续,而物理地址则无需连续,因此不能用于dma缓冲区
- 通过vmalloc获得的页必须一个一个地进行映射,效率不高,因此不得已时才使用,同时vmalloc分配的一般是大块内存
- vmalloc分配的一般是高端内存,只有当内存不够的时候,才会分配低端内存
1. 数据结构
在进行vmalloc代码走读之前,先简单看一下两个重要的数据结构:struct vm_struct(vmalloc描述符)和struct vmap_area(记录在vmap_area_root中的vmalooc分配情况和vmap_area_list列表中)。内核在管理虚拟内存中的vmalloc区域时,必须跟踪哪些区域被使用,哪些是空闲的,为此定义了一个数据结构,将所有的部分保存在一个链表中
struct vm_struct {
struct vm_struct *next;
void *addr;
unsigned long size;
unsigned long flags;
struct page **pages;
unsigned int nr_pages;
phys_addr_t phys_addr;
const void *caller;
};
| 结构体变量 | 描述 |
|---|---|
| *next | 所有的vm_struct通过next组成一个单链表,表头为全局变量vmlist |
| *addr | 定义了这个虚拟地址空间子区域的起始地址 |
| size | 定义了这个虚拟地址空间子区域的大小 |
| flags | 存储了与该内存区关联的标志位 |
| **pages | 指向page指针的数组,每个数组成员都表示一个映射到这个地址空间的物理页面的实例 |
| nr_pages | page指针数据的长度 |
| phys_addr | 仅当用ioremap映射了由物理地址描述的物理内存区域才有效 |
在创建一个新的虚拟内存区之前,必须要找到一个适合的位置。v
struct vmap_area {
unsigned long va_start;
unsigned long va_end;
unsigned long flags;
struct rb_node rb_node; /* address sorted rbtree */
struct list_head list; /* address sorted list */
struct llist_node purge_list; /* "lazy purge" list */
struct vm_struct *vm;
struct rcu_head rcu_head;
};
| 成员变量 | 描述 |
|---|---|
| va_start | vmalloc区的虚拟区间起始地址 |
| va_end | vmalloc区的虚拟区间结束地址 |
| flags | 类型标识 |
| rb_node | 插入红黑树vmap_area_root的节点 |
| list | 用于加入链表vmap_area_list的节点 |
| purge_list | 用于加入到全局链表vmap_purge_list中 |
| vm | 指向对应的vm_struct |
struct vmap_area用于描述一段虚拟地址的区域,从结构体中va_start/va_end也能看出来。同时该结构体会通过rb_node挂在红黑树上,通过list挂在链表上。
struct vmap_area中vm字段是struct vm_struct结构,用于管理虚拟地址和物理页之间的映射关系,可以将struct vm_struct构成一个链表,维护多段映射。
2. 初始化
在系统初始化的时候,会通过mm_init初始化vmalloc,其初始化流程如下
void __init vmalloc_init(void)
{
struct vmap_area *va;
struct vm_struct *tmp;
int i;
for_each_possible_cpu(i) { ------------(1)
struct vmap_block_queue *vbq;
struct vfree_deferred *p;
vbq = &per_cpu(vmap_block_queue, i);
spin_lock_init(&vbq->lock);
INIT_LIST_HEAD(&vbq->free);
p = &per_cpu(vfree_deferred, i);
init_llist_head(&p->list);
INIT_WORK(&p->wq, free_work);
}
/* Import existing vmlist entries. */
for (tmp = vmlist; tmp; tmp = tmp->next) { -------------(2)
va = kzalloc(sizeof(struct vmap_area), GFP_NOWAIT);
va->flags = VM_VM_AREA;
va->va_start = (unsigned long)tmp->addr;
va->va_end = va->va_start + tmp->size;
va->vm = tmp;
__insert_vmap_area(va);
}
vmap_area_pcpu_hole = VMALLOC_END;
vmap_initialized = true;
}
- 先遍历每CPU的vmap_block_queue和vfree_deferred变量并进行初始化。其中vmap_block_queue是非连续内存块队列管理结构,主要是队列以及对应的保护锁;而vfree_deferred是vmalloc的内存延迟释放管理,除了队列初始外,还创建了一个free_work()工作队列用于异步释放内存。
- 接着将挂接在vmlist链表的各项__insert_vmap_area()输入到非连续内存块的管理中,而vmlist的初始化是通过iotable_init初始化(arm32),最终所有的vmalloc的eara都会挂到vmap_area_list链表中
3. vmalloc分配
vmalloc为内核分配了一个连续的@size虚拟地址空间,然后调用__vmalloc_node_flags()函数
void *vmalloc(unsigned long size)
{
return __vmalloc_node_flags(size, NUMA_NO_NODE,
GFP_KERNEL | __GFP_HIGHMEM);
}
__vmalloc_node_flags请求节点为内核分配连续的虚拟内存
static inline void *__vmalloc_node_flags(unsigned long size,
int node, gfp_t flags)
{
return __vmalloc_node(size, 1, flags, PAGE_KERNEL,
node, __builtin_return_address(0));
}
对于内核,@node分配连续的虚拟内存,但是虚拟地址使用VMALLOC地址空间的空白空间映射虚拟地址[VMALLOC_START, VMALLOC_END]
static void *__vmalloc_node(unsigned long size, unsigned long align,
gfp_t gfp_mask, pgprot_t prot,
int node, const void *caller)
{
return __vmalloc_node_range(size, align, VMALLOC_START, VMALLOC_END,
gfp_mask, prot, 0, node, caller);
}
请求节点分配连续的虚拟内存,但虚拟地址使用指定范围内的空白空间映射虚拟地址
void *__vmalloc_node_range(unsigned long size, unsigned long align,
unsigned long start, unsigned long end, gfp_t gfp_mask,
pgprot_t prot, unsigned long vm_flags, int node,
const void *caller)
{
struct vm_struct *area;
void *addr;
unsigned long real_size = size;
size = PAGE_ALIGN(size); -------------------(1)
if (!size || (size >> PAGE_SHIFT) > totalram_pages)
goto fail;
area = __get_vm_area_node(size, align, VM_ALLOC | VM_UNINITIALIZED | -------------------(2)
vm_flags, start, end, node, gfp_mask, caller);
if (!area)
goto fail;
addr = __vmalloc_area_node(area, gfp_mask, prot, node); --------------------(3)
if (!addr)
return NULL;
clear_vm_uninitialized_flag(area); --------------------(4)-
kmemleak_alloc(addr, real_size, 2, gfp_mask);
return addr;
fail:
warn_alloc(gfp_mask,
"vmalloc: allocation failure: %lu bytes", real_size);
return NULL;
}
- 检查size正确性,不能为0且不能大于totalram_pages,totalram_pages是bootmem分配器移交给伙伴系统的物理内存页数总和,则通过故障标签返回null
- 请求虚拟地址范围内找到一个可以包含请求大小的空位置,并使用该虚拟地址配置vmap_area和vm_struct信息,然后将其返回,其最终是分配一个vm_struct结构,获取对应长度(注意额外加一页)高端连续地址,最终插入vmlist链表,也就是向内核请求一个空间大小相匹配的虚拟地址空间,返回管理信息结构vm_struct
- alloc_vmap_area作用就是根据所要申请的高端地址的长度size(注意这里的size已经是加上一页隔离带的size),在vmalloc区找到一个合适的区间并把起始虚拟地址和结尾地址通知给内核
- 标示内存空间初始化,最后调用kmemleak_alloc()进行内存分配泄漏调测,并将虚拟地址返回
操作流程比较简单,下面是整个流程图如下:
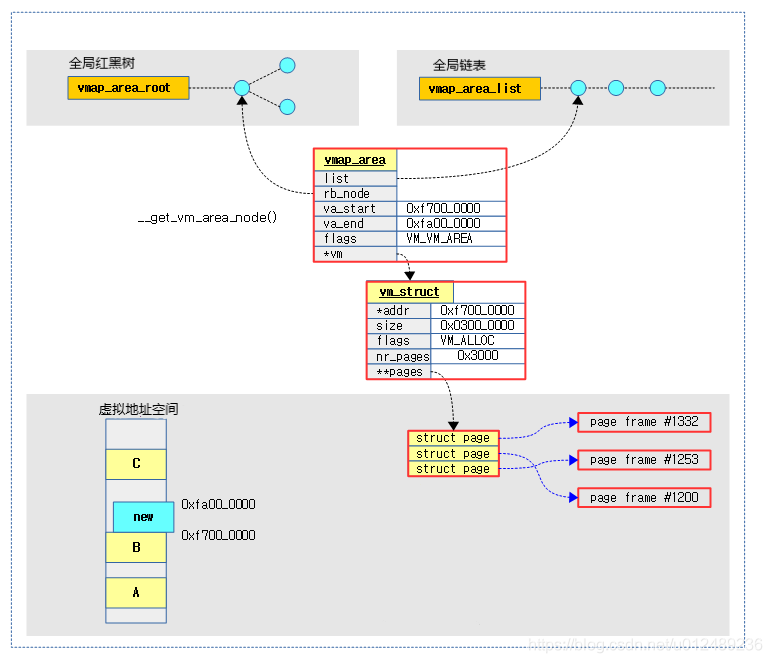
__vmalloc_node_range是vmalloc的核心函数,其主要是完成找到符合大小的空闲vmalloc区域,其代码流程如下
static struct vm_struct *__get_vm_area_node(unsigned long size,
unsigned long align, unsigned long flags, unsigned long start,
unsigned long end, int node, gfp_t gfp_mask, const void *caller)
{
struct vmap_area *va;
struct vm_struct *area;
BUG_ON(in_interrupt()); //vmalloc不能中在中断中被调用
size = PAGE_ALIGN(size); //页对齐操作
if (unlikely(!size))
return NULL;
if (flags & VM_IOREMAP)
align = 1ul << clamp_t(int, get_count_order_long(size),
PAGE_SHIFT, IOREMAP_MAX_ORDER);
area = kzalloc_node(sizeof(*area), gfp_mask & GFP_RECLAIM_MASK, node); //分配一个struct vm_struct来描述vmalloc区域
if (unlikely(!area))
return NULL;
if (!(flags & VM_NO_GUARD)) //加一页作为安全区间
size += PAGE_SIZE;
va = alloc_vmap_area(size, align, start, end, node, gfp_mask); //申请一个vmap_area并将其插入vmap_area_root中
if (IS_ERR(va)) {
kfree(area);
return NULL;
}
setup_vmalloc_vm(area, va, flags, caller); //填充vmalloc描述符vm_struct area
return area;
}
__vmalloc_area_node则进行实际的页面分配,并建立页表映射,更新页表cache,其代码流程如下
static void *__vmalloc_area_node(struct vm_struct *area, gfp_t gfp_mask,
pgprot_t prot, int node)
{
struct page **pages;
unsigned int nr_pages, array_size, i;
const gfp_t nested_gfp = (gfp_mask & GFP_RECLAIM_MASK) | __GFP_ZERO; //添加__GFP_ZERO,仅保留与页数相关的标志
const gfp_t alloc_mask = gfp_mask | __GFP_NOWARN; //将__GFP_NOWARN添加到gfp_mask
nr_pages = get_vm_area_size(area) >> PAGE_SHIFT; //申请多少pages
array_size = (nr_pages * sizeof(struct page *)); //需要多大的存放page指针的空间
area->nr_pages = nr_pages;
/* Please note that the recursion is strictly bounded. */
if (array_size > PAGE_SIZE) { // 这里默认page_size 为4k 即4096
pages = __vmalloc_node(array_size, 1, nested_gfp|__GFP_HIGHMEM,
PAGE_KERNEL, node, area->caller);
} else { //小于一页,则直接利用slab机制申请物理空间地址给pages
pages = kmalloc_node(array_size, nested_gfp, node);
}
area->pages = pages;
if (!area->pages) {
remove_vm_area(area->addr);
kfree(area);
return NULL;
}
for (i = 0; i < area->nr_pages; i++) { //每次申请一个page利用alloc_page直接申请物理页面
struct page *page;
if (node == NUMA_NO_NODE)
page = alloc_page(alloc_mask);
else
page = alloc_pages_node(node, alloc_mask, 0);
if (unlikely(!page)) {
/* Successfully allocated i pages, free them in __vunmap() */
area->nr_pages = i;
goto fail;
}
area->pages[i] = page; //分配的地址存放在指针数组
if (gfpflags_allow_blocking(gfp_mask))
cond_resched();
}
if (map_vm_area(area, prot, pages)) //修改页表 ,一页一页的实现映射,以及flush cache保持数据的一致性
goto fail;
return area->addr;
fail:
warn_alloc(gfp_mask,
"vmalloc: allocation failure, allocated %ld of %ld bytes",
(area->nr_pages*PAGE_SIZE), area->size);
vfree(area->addr);
return NULL;
}
__vmalloc_area_node()已经分配了所需的物理页框,但是这些分散的页框并没有映射到area所代表的那个连续vmalloc区中。map_vm_area()将完成映射工作,它依次修改内核使用的页表项,将pages数组中的每个页框分别映射到连续的vmalloc区中。其整个流程如下:
- 1.通过__get_vm_area_node()函数查找一个足够大的空间的虚拟地址段,然后再通过kmalloc分配一个新的vm_struct结构体
- 2.计算当前分配的内存大小需要占用多少个page,然后通过kmalloc分配一组struct page指针数组,再通过调用buddy allocator接口alloc_page()每次获取一个物理页框填入到vm_struct中的struct page* 数则
- 3.分配PMD,PTE更新内核页表,返回映射后的虚拟地址。
此次,vmalloc在虚拟内存空间给出一块连续的内存区,实质上,这片连续的虚拟内存在物理内存中并不一定连续,所以vmalloc申请的虚拟内存和物理内存之间也就没有简单的换算关系,正因如此,vmalloc()通常用于分配远大于__get_free_pages()的内存空间,它的实现需要建立新的页表,此外还会调用使用GFP_KERN的kmalloc,一定不要在中断处理函数,tasklet和内核定时器等非进程上下文中使用vmalloc!
4. 其他分配
除了vmalloc之外,还有其他可以创建虚拟连续映射。
- vmalloc_32分配适用于32位地址的内存区域。该函数会保证物理pages是从ZONE_NORMAL中进行分配并且要求当前设备是32位的,其工作方式与vmalloc相同
- vmap使用一个page数组作为七点,来创建虚拟连续内存区。与vmalloc相比,该函数所用的物理内存位置不是隐式分配的,而需要先行分配好,作为参数传递。
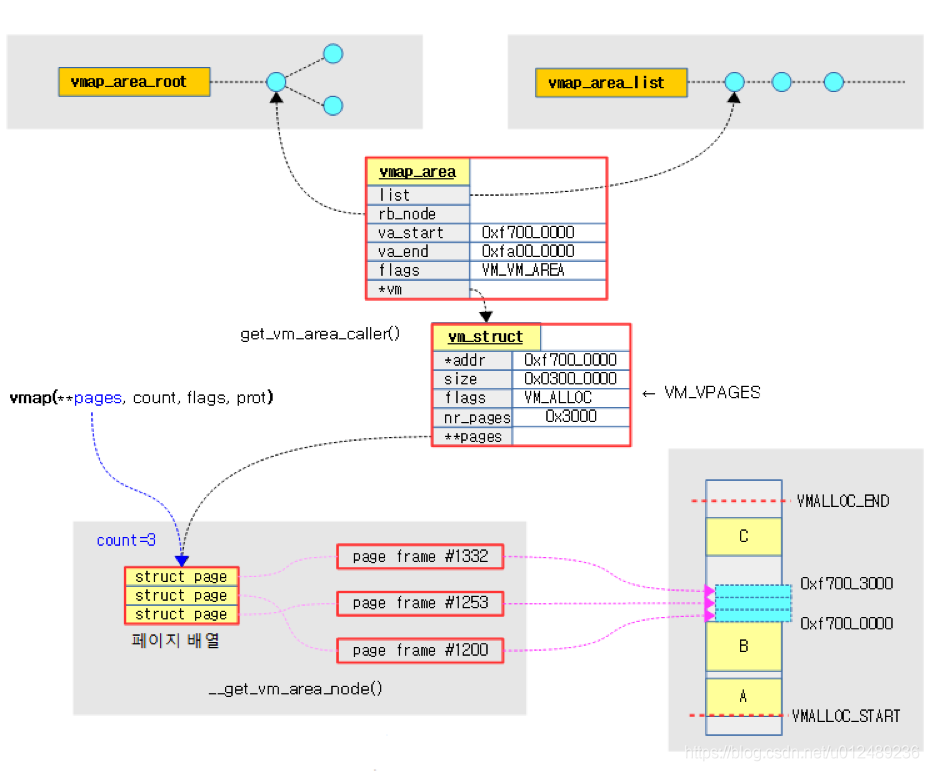
本节的重点是介绍下vmap的流程,vmap函数完成的工作是,在vmalloc虚拟地址空间中找到一个空闲区域,然后将page页面数组对应的物理内存映射到该区域,最终返回映射的虚拟起始地址。
void *vmap(struct page **pages, unsigned int count,
unsigned long flags, pgprot_t prot)
{
struct vm_struct *area;
unsigned long size; /* In bytes */
might_sleep(); ---------------(1)
if (count > totalram_pages)
return NULL;
size = (unsigned long)count << PAGE_SHIFT; ---------------(2)
area = get_vm_area_caller(size, flags, __builtin_return_address(0));
if (!area)
return NULL;
if (map_vm_area(area, prot, pages)) { ---------------(3)
vunmap(area->addr);
return NULL;
}
return area->addr;
}
- 1.如果有任务紧急请求重新安排作为抢占点,则它将休眠;如果请求的页数比所有内存页数多,则放弃处理并返回null
- 2.VM分配配置vmap_area和vm_struct信息。失败时,将返回null
- 3.map_vm_area尝试映射具有vm_struct信息的页面,如果不成功,则在取消后返回null,如果成功,就返回映射的虚拟地址空间的起始地址
其整个代码流程如下:

下图通过在vmap虚拟地址空间中找到空白空间来显示请求的物理页面的映射。
5. 释放内存
有两个函数用于向内核释放内存,这两个函数都最终归结到vunmap
- vfree用于释放vmalloc和vmalloc_32分配的区域
- vunmap用于释放由vmap和Ioremap创建的映射
释放由vmalloc()分配和映射的连续虚拟地址内存。当通过中断处理程序调用时,映射的连续虚拟地址内存无法立即释放,因此在将工作队列中注册的free_work()函数添加到每个CPU vfree_deferred中以进行延迟处理后,对其进行调度。
void vfree(const void *addr)
{
BUG_ON(in_nmi());
kmemleak_free(addr);
if (!addr)
return;
if (unlikely(in_interrupt())) {
struct vfree_deferred *p = this_cpu_ptr(&vfree_deferred);
if (llist_add((struct llist_node *)addr, &p->list))
schedule_work(&p->wq);
} else
__vunmap(addr, 1);
}
vmap()函数取消映射到vmalloc地址空间的虚拟地址区域的映射。但是,物理页面不会被释放。
void vunmap(const void *addr)
{
BUG_ON(in_interrupt());
might_sleep();
if (addr)
__vunmap(addr, 0);
}
vunmap执行的是跟vmap相反的过程:从vmap_area_root/vmap_area_list中查找vmap_area区域,取消页表映射,再从vmap_area_root/vmap_area_list中删除掉vmap_area,页面返还给伙伴系统等。由于映射关系有改动,因此还需要进行TLB的刷新,频繁的TLB刷新会降低性能,因此将其延迟进行处理,因此称为lazy tlb。
static void __vunmap(const void *addr, int deallocate_pages)
{
struct vm_struct *area;
if (!addr)
return;
if (WARN(!PAGE_ALIGNED(addr), "Trying to vfree() bad address (%p)\n",
addr))
return;
area = remove_vm_area(addr);
if (unlikely(!area)) {
WARN(1, KERN_ERR "Trying to vfree() nonexistent vm area (%p)\n",
addr);
return;
}
debug_check_no_locks_freed(addr, get_vm_area_size(area));
debug_check_no_obj_freed(addr, get_vm_area_size(area));
if (deallocate_pages) {
int i;
for (i = 0; i < area->nr_pages; i++) {
struct page *page = area->pages[i];
BUG_ON(!page);
__free_pages(page, 0);
}
kvfree(area->pages);
}
kfree(area);
return;
}
addr表示要释放的区域的起始地址,deallocate_pages指定了是否将与该区域相关的物理内存页返回给伙伴系统。其代码流程如下图

6. 总结
本章大致梳理了对于物理内存不连续,虚拟内存连续的内存申请的方式,vmalloc和vmap的操作,大部分的逻辑操作是一样的,比如从VMALLOC_START ~ VMALLOC_END区域之间查找并分配vmap_area, 比如对虚拟地址和物理页框进行映射关系的建立。
不同之处,在于
vmap建立映射时,page是函数传入进来的,而vmalloc是通过调用alloc_page接口向Buddy System申请分配的。
我们应该能清楚vmalloc和kmalloc的差异了吧,kmalloc会根据申请的大小来选择基于slub分配器或者基于Buddy System来申请连续的物理内存。而vmalloc则是通过alloc_page申请order = 0的页面,再映射到连续的虚拟空间中,物理地址不连续,此外vmalloc可以休眠,不应在中断处理程序中使用。
与vmalloc相比,kmalloc使用ZONE_DMA和ZONE_NORMAL空间,性能更快,缺点是连续物理内存空间的分配容易带来碎片问题,让碎片的管理变得困难,结合前面学习的伙伴系统和slab分配方式,总结如下

这些都是内核空间的内存分配的方式,后面章节会讲解对于用户空间的内存分配的方式。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
