在Linux系统中,前面我们接触了用户进程或用户进程,但是在实际的也是有内核线程的存在,例如我们在内存管理章节中熟悉的内存回收进程kswapd,软中断等。本章主主要包括内核线程的创建和结束的完整过程。
1. Linux线程管理
Linux内核在启动的时候,是没有线程的概念,当内核初始化完成后将启动一系列的线程,之后,CPU执行流就绑定在一个线程中运行,内核线程和用户线程的区别如下图所示:
- 每一个线程创建之初都是内核线程;创建之后如果与具体的进程上下文绑定,那线程就成了用户线程
- 如果绑定的内核线程,那么执行内核线程的服务代码,对于内核线性是没有地址空间的概念,准确的来说是没有用户地址空间的概念,使用的是所有进程共享的内核地址空间,但是调度的时候会借用前一个进程的地址空间

1.1 线程主要数据结构
内核线程也是用task_struct的数据结构表示,其跟用户空间的数据结构含义基本类似,我们重点关注以下内容

1.2 线程内核接口
Linux线程的实现相当复杂,但使用却比较简单。使用接口封装成了几个函数,其他模块只需直接使用这些函数,比如只需调用一句宏即可
struct task_struct *kthread_create_on_node(int (*threadfn)(void *data),
void *data,
int node,
const char namefmt[], ...);
#define kthread_create(threadfn, data, namefmt, arg...) \
kthread_create_on_node(threadfn, data, NUMA_NO_NODE, namefmt, ##arg)
struct task_struct *kthread_create_on_cpu(int (*threadfn)(void *data),
void *data,
unsigned int cpu,
const char *namefmt);
#define kthread_run(threadfn, data, namefmt, ...) \
({ \
struct task_struct *__k \
= kthread_create(threadfn, data, namefmt, ## __VA_ARGS__); \
if (!IS_ERR(__k)) \
wake_up_process(__k); \
__k; \
})
1.3 内核线程和用户线程
CPU在执行和调度中并不会区分是用户线程还是内核线程,用户线程无非就是多一个用户空间的堆栈管理而已 。本文讲解包括用户线程和内核线程在内的创建逻辑。

Linux用户线程(属于用户进程),都是在用户空间创建,虽然线程是内核调度的基本单位,但是用户线程的堆栈并不是由内核管理,它是由系统库创建和管理。所以,用户的线程的资源是由用户库来管理的,和内核线程堆没有必然的关系,唯一依赖的就是靠内核的线程对象来调度执行。详细的过程参考pthread的库实现,其最终会调用到底层的clone接口。


内核线程通过kthread_create_on_node()函数创建,下面我们来看看内核线程的实现过程
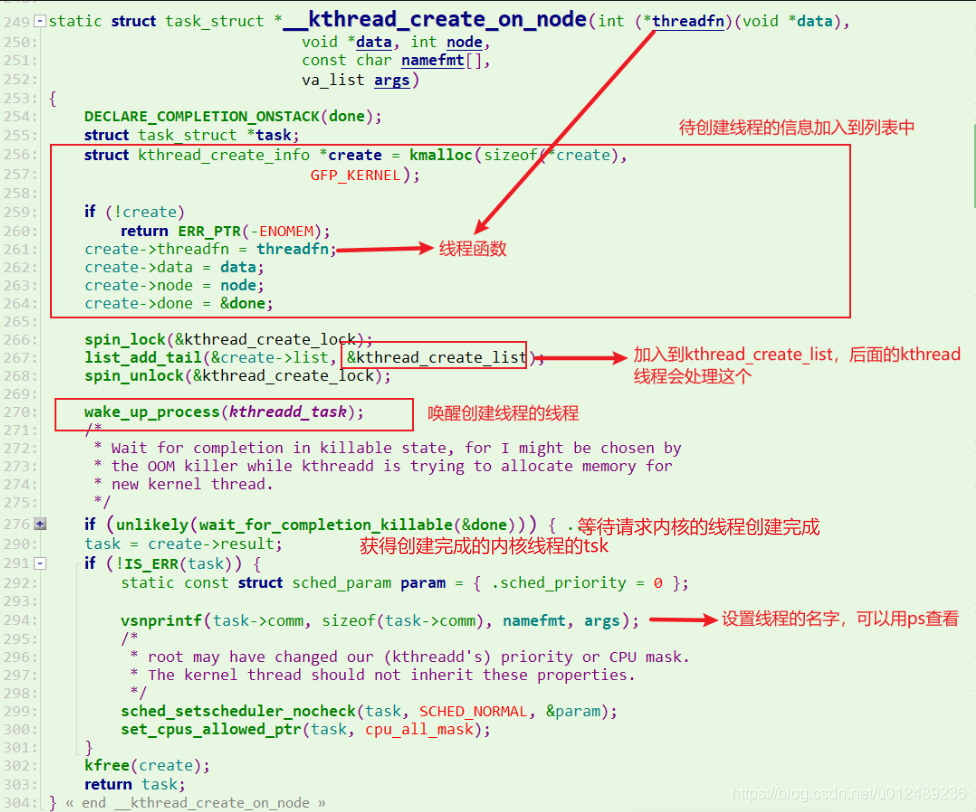
函数已经做了详细的注释,这里主要完成以下内容
- 首先将需要在内核线程中执行的函数等信息封装到kthread_create_info结构体中,然后加入到kthreadd的kthread_create_list链表中
- 接着去唤醒kthreadd去处理创建的内核线程请求,由它来执行具体的创建工作,之后通过一个completion对象等待创建结构
- 创建成功后,线程就可以调度执行了
2. 内核线程的创建
内核专门提供了Kthreadd线程用来处理内核线程,kthreadd线程在内核启动的时候就创建好了,一直不会退出,当没有创建任务时,主动放弃CPU时间,调用schedule()执行调度程序;当任务到来后,它会被再次唤醒,执行具体的创建线程任务。

- kthreadd函数中设置了线程名字和亲和性属性之后,然后进入循环处理流程
- 首先将自己的状态置为TASK_INTERRUPTIBLE,然后判断kthread_create_list链表是否为空,这个链表存放其他内核路径的创建内核线程的请求结构struct kthread_create_info,对于创建内核线程时,会封装kthread_create_info结构然后加入到kthread_create_list
- 如果kthread_create_list链表为空,说明没有创建内核线程请求,直接调用schedule进行睡眠;当某个内核路径有kthread_create_info加入到kthread_create_list链表中并唤醒kthreadd后,kthreadd从__set_current_state(TASK_RUNNING)开始执行,设置状态为运行状态,然后进入一个循环,不断的从kthread_create_list.next取出kthread_create_info结构,并从链表中删除,调用create_kthread创建一个内核线程来执行剩余的工作
- create_kthread很简单,就是创建内核线程,然后执行 kthread函数 ,将取到的kthread_create_info结构传递给这个函数

create_thread()函数实际上调用kernel_thread(),而它又最终调用_do_fork()创建线程。 创建的时候并不会把线程函数直接传递进去,而是先传入一个公共的代理函数,待代理函数起来,并进行一些初始化后,才开始执行线程函数 。

通知completion对象,创建工作已经完成,线程已经运行起来了,接着主动调用schedule()放弃CPU时间,以便创建者可以快速的获得调度,知道创建结果。
_do_fork()不会重头分配每一个task_struct对象的数据,而是从父线程那里拷贝一个副本回来,跟据参数不同,拷贝的内容也各有差异,这里不去细分如何差别对待拷贝参数,可以看前面的章节 进程管理(八)–创建进程fork_奇小葩-CSDN博客
3 内核线程的结束
内核线程一旦启动起来后,会一直运行,除非该线程主动调用do_exit函数,或者其他的进程调用kthread_stop函数,结束线程的运行。如果线程函数正在处理一个非常重要的任务,它不会被中断的。当然如果线程函数永远不返回并且不检查信号,它将永远都不会停止。
在线程函数里,完成所需要的业务逻辑工作

值得一提的是kthread_should_stop函数,我们需要在开启的线程中嵌入该函数并检查此函数的返回值,否则kthread_stop是不起作用的

这个函数在kthread_stop()被调用后返回真,当返回为真时你的处理函数要返回,返回值会通过kthread_stop()返回。所以你的处理函数应该有判断kthread_should_stop然后退出的代码

4 总结
内核线程起始就是运行在内核地址空间的进程,它和普通的用户进程的区别在于内核线程没有独立的进程地址空间,即task_struct数据结构中mm指针为NULL,它只能运行在内核地址空间,和普通的进程一样参与系统的调度中。所有的内核线程都共享内核地址空间。
