
前面 9 篇文章我们已经深入了解了 NIO 的基本概念和核心原理,想必小伙伴们对 NIO 的三大组件已经了然于心了,对于 ByteBuffer 而言,其实还有两个较为特殊的类 DirectByteBuffer 和 MappedByteBuffer 没有分析,这两个类的原理都是基于内存文件映射的。
ByteBuffer 分为两种,一种是直接的,另外一种是间接的。
- 直接缓冲:直接使用内存映射,对于 Java 而言就是直接在 JVM 之外分配虚拟内存地址空间,Java 中使用 DirectByteBuffer 来实现,也就是堆外内存。
- 间接缓冲:是在 JVM 堆上实现,Java 中使用 HeapByteBuffer 来实现,也就是堆内内存。
我们这篇文章主要分析直接缓冲,即 DirectByteBuffer。在了解 DirectByteBuffer 之前我们需要先了解操作系统的内存管理方面的知识点。
虚拟内存与物理内存
我们先了解几个基本概念。
- MMC:Memory Management Unit,CPU的内存管理单元,用来管理虚拟存储器、物理存储器的控制线路,虚拟地址到物理地址的映射。
- 物理内存:即内存条的内存空间,我们可以理解为真实的内存。
- 虚拟内存:计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。
- 页面文件:操作系统反映构建并使用虚拟内存的硬盘空间大小而创建的文件,在 windows 下,即 pagefile.sys 文件,其存在意味着物理内存被占满后,将暂时不用的数据移动到硬盘上。
- 缺页中断:当程序试图访问已映射在虚拟地址空间中但未被加载至物理内存的一个分页时,由 MMC 发出的中断。如果操作系统判断此次访问是有效的,则尝试将相关的页从虚拟内存文件中载入物理内存。
对于操作系统而言,为什么会有真实内存(物理内存)和虚拟内存之分呢?这是因为如果我们只使用物理内存会有很多问题。
-
程序运行困难。为什么会困难,因为内存有限。对于 32 位的系统而言,每个进程在运行的时候都需要分配 4G(2^32) 的内存,对于一个系统而言,你有多少物理内存可供分配,而且在很多应用中我们服务器的标配一般都是 2C4G,这只能运行一个进程了。
-
没有虚拟内存,我们程序就直接访问物理内存了,这就意味着一个程序可以任意访问内存中的所有地址,如果有人搞破坏修改了其他程序在用的地址中的数据,这就可能导致其他程序崩溃。
虚拟内存的出现解决了上面的问题,进程运行时都会分配 4G 的虚拟内存,进程认为它有了 4G 的内存空间了(只是它以为),但实际上,在虚拟内存对应的物理内存上可能只有一点点,实际用了多少内存就会对应多少物理内存。同时进程得到的 4G 虚拟内存是一个连续的内存空间(也只是它认为的),而实际上,它通常会被分割为多个物理内存碎片,而且可能有一部分内存还存储在磁盘上,在需要的时候进行数据交换。
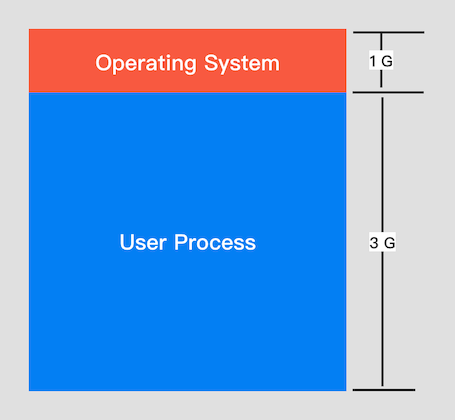
对我们常用的 Linux 操作系统而言,虚拟内存一般都是 4G,其中 1G 为系统内存,3G 为应用程序内存。
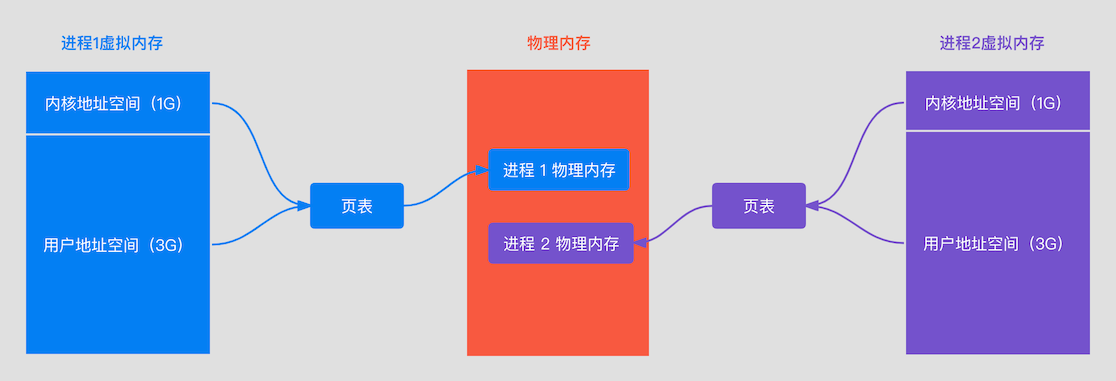
进程使用的是虚拟内存,但是我们数据还是存储在物理内存上,那虚拟内存是怎样和物理内存对应起来的呢? 页表,虚拟内存和物理内存建立对应关系采用的是页表页映射的方式,如下:
页表记录了虚拟内存每个页和物理内存之间的对应关系,如下图:
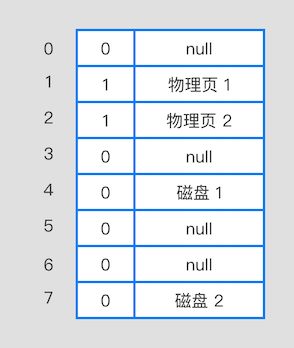
它有两个栏位:有效位和路径
- 有效位:有效位有两个值,0 和 1 ,其中 1 表示已经在物理内存上了,0 表示不在物理内存上
- 路径:具体的物理页号编码或者磁盘地址
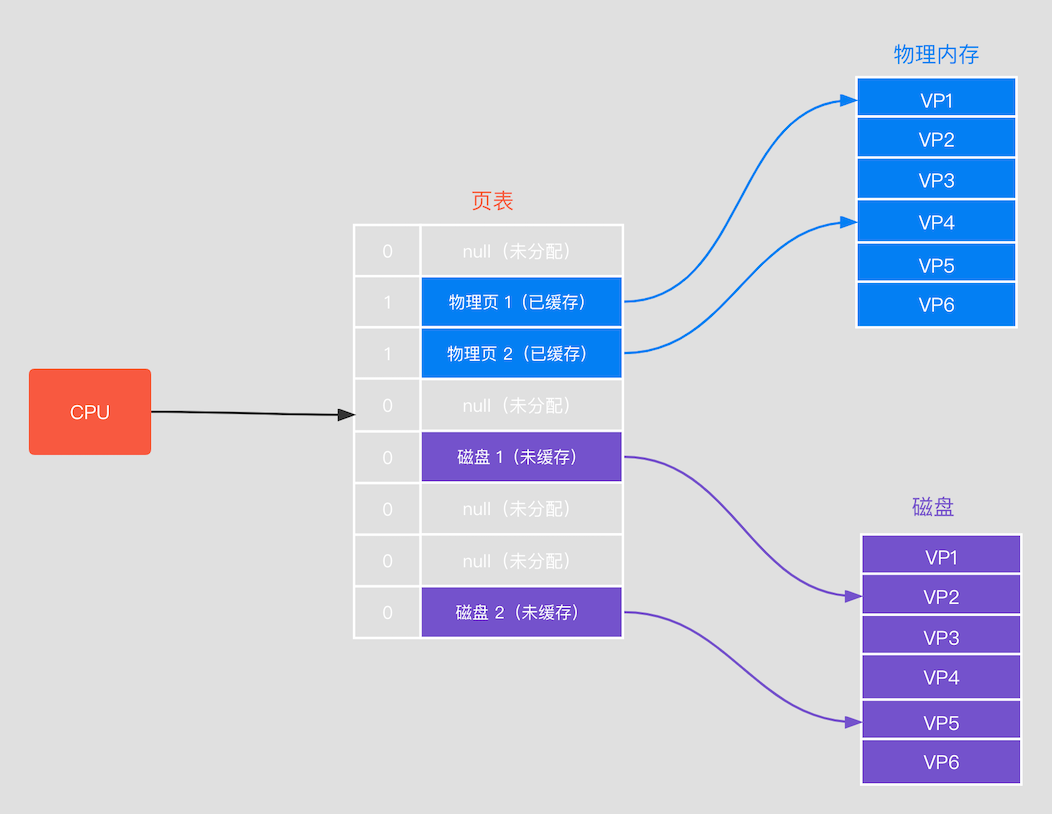
当 CPU 寻址时,它有三种状态:
- 未分配:虚拟地址所在的那一页并未被分配,代表没有数据和他们关联,这部分也不会占用物理内存。
- 未缓存:虚拟地址所在的那一页被分配了,但并不在物理内存中。
- 已缓存:虚拟地址所在的那一页就在物理内存中。
CPU 访问虚拟内存地址过程如下:
- 首先查看页表,判断该页的有效位是否为 1,如果为 1,则命中缓存,根据物理内存页号编码找到物理内存当中的内容,返回。
- 如果有效位为 0,表示不在物理内存上,则参数缺页异常,调用系统内核缺页异常处理程序,操作系统会立刻阻塞该进程,并将磁盘中对应的页加载到物理内存且有效位设置为 1,然后使该进行就绪。如果物理内存满了,则会通过页面置换算法选择一个页来覆盖即可。
内存映射
下图是 Linux 进程的虚拟内存结构:
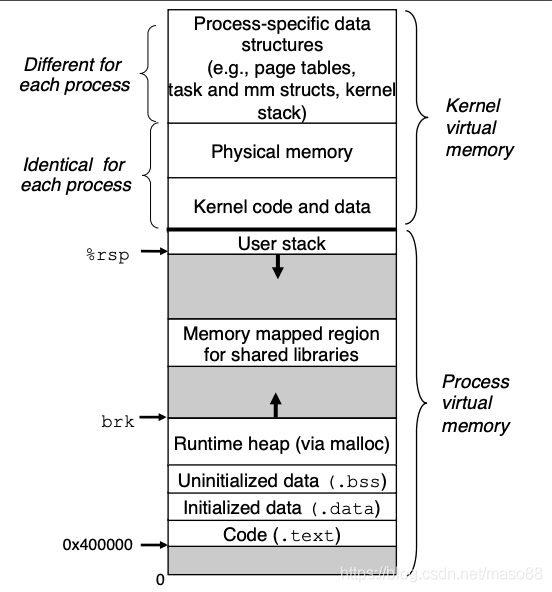
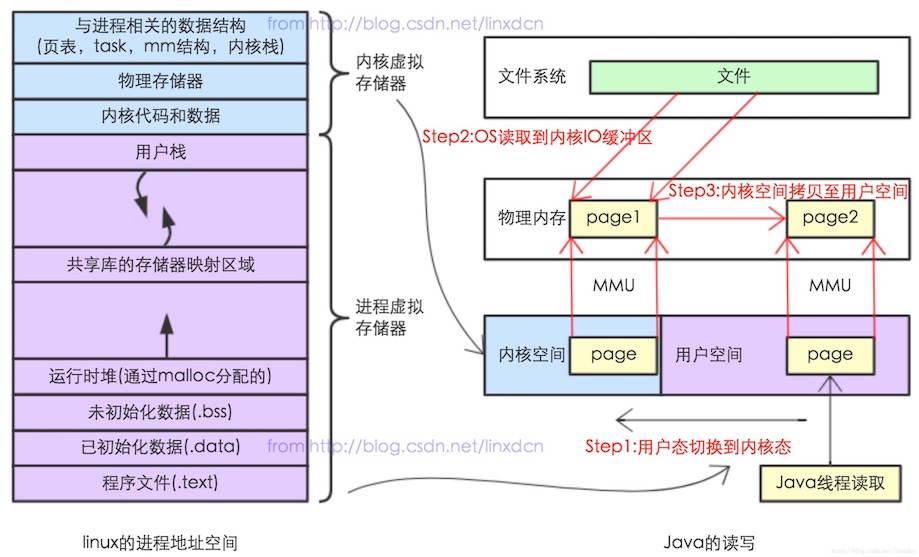
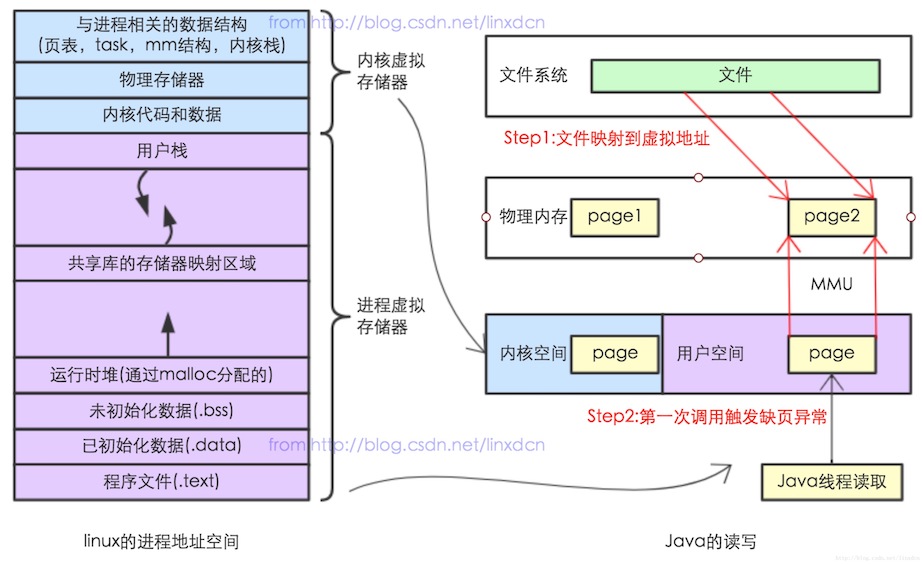
注意其中一块区域“Memory mapped region for shared libraries”,这块区域就是内存映射文件的时候将某一段的虚拟地址和文件对象的某一部分建立映射关系,此时并没有拷贝数据到内存中,而是当进程代码第一次引用这段代码内的虚拟地址时,触发了缺页异常,这时候 OS 根据映射关系直接将文件的相关部分数据拷贝到进程的用户私有空间中去,当有操作第 N 页数据的时候重复这样的 OS 页面调度程序操作。这样就减少了文件拷贝到内核空间,再拷贝到用户空间,效率比标准 IO 高。下面两张图片是标准 IO 操作和内存映射文件,小伙伴们可以认真对比下(图片来自:https://blog.csdn.net/linxdcn/article/details/72903422)。
- 标准 IO
- 内存文件映射
MappedByteBuffer
先看 MappedByteBuffer 和 DirectByteBuffer 的类图:
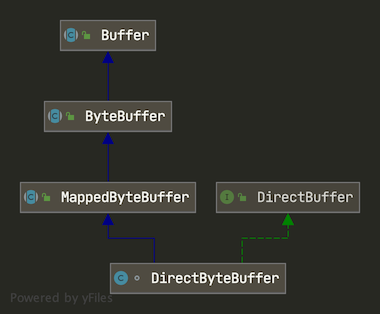
MappedByteBuffer 是一个抽象类,DirectByteBuffer 则是他的子类。
MappedByteBuffer 作为抽象类,其实它本身还是非常简单的。定义如下
public abstract class MappedByteBuffer extends ByteBuffer {
// 文件描述符
private final FileDescriptor fd;
// package 访问级别
// 只能通过子类 DirectByteBuffer 构造函数调用
MappedByteBuffer(int mark, int pos, int lim, int cap, FileDescriptor fd) {
super(mark, pos, lim, cap);
this.fd = fd;
}
MappedByteBuffer(int mark, int pos, int lim, int cap) {
super(mark, pos, lim, cap);
this.fd = null;
}
// 省略一些代码
}
其实在父类 Buffer 中有一个非常重要的属性 address
// Used only by direct buffers
// NOTE: hoisted here for speed in JNI GetDirectBufferAddress
long address;
这个属性表示分配堆外内存的地址,是为了在 JNI 调用 GetDirectBufferAddress 时提升它调用的速率。这个属性我们在后面会经常用到,到时候再分析。
MappedByteBuffer 作为抽象类,我们可以通过调用 FileChannel 的 map() 方法来创建,如下:
FileInputStream inputStream = new FileInputStream("/Users/chenssy/Downloads/test.txt");
FileChannel fileChannel = inputStream.getChannel();
MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_ONLY, 0,fileChannel.size());
map() 方法定义如下:
public abstract MappedByteBuffer map(MapMode mode, long position, long size)
throws IOException;
该方法可以把文件的从 position 开始的 size 大小的区域映射为 MappedByteBuffer,mode 定义了可访问该内存映射文件的访问方式,共有三种
MapMode.READ_ONLY(只读): 试图修改得到的缓冲区将导致抛出 ReadOnlyBufferException。MapMode.READ_WRITE(读/写): 对得到的缓冲区的更改最终将写入文件;但该更改对映射到同一文件的其他程序不一定是可见的。MapMode.PRIVATE(专用): 可读可写,但是修改的内容不会写入文件,只是buffer自身的改变,这种能力称之为”copy on write”
MappedByteBuffer 作为 ByteBuffer 的子类,它同时也是一个抽象类,相比 ByteBuffer ,它新增了三个方法:
isLoaded():如果缓冲区的内容在物理内存中,则返回真,否则返回。load():将缓冲区的内容载入内存,并返回该缓冲区的引用。force():缓冲区是READ_WRITE模式下,此方法对缓冲区内容的修改强行写入文件。
与传统 IO 性能对比
相比传统 IO, MappedByteBuffer 就一个字,快!!!,它快就在于它采用了 direct buffer(内存映射) 的方式来读取文件内容。这种方式是直接调动系统底层的缓存,没有 JVM,少了内核空间和用户空间之间的复制操作,所以效率大大提高了。那它相比传统 IO 它快了多少呢?下面我们来做个小实验。
- 首先我们写一个程序用来生成文件。
int size = 1024 * 10;
File file = new File("/Users/chenssy/Downloads/fileTest.txt");
byte[] bytes = new byte[size];
for (int i = 0 ; i < size ; i++) {
bytes[i] = new Integer(i).byteValue();
}
FileUtil.writeBytes(bytes,file);
通过更改 size 的数字,我们可以生成 10k,1M,10M,100M,1G 五个文件,我们就这两个文件来对比 MappedByteBuffer 和 传统 IO 读取文件内容的性能。
- 传统 IO 读取文件
File file = new File("/Users/chenssy/Downloads/fileTest.txt");
FileInputStream in = new FileInputStream(file);
FileChannel channel = in.getChannel();
ByteBuffer buff = ByteBuffer.allocate(1024);
long begin = System.currentTimeMillis();
while (channel.read(buff) != -1) {
buff.flip();
buff.clear();
}
long end = System.currentTimeMillis();
System.out.println("time is:" + (end - begin));
- MappedByteBuffer 读取文件
int BUFFER_SIZE = 1024;
File file = new File("/Users/chenssy/Downloads/fileTest.txt");
FileChannel fileChannel = new FileInputStream(file).getChannel();
MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_ONLY, 0,fileChannel.size());
byte[] b = new byte[1024];
int length = (int) file.length();
long begin = System.currentTimeMillis();
for (int i = 0 ; i < length ; i += 1024) {
if (length - i > BUFFER_SIZE) {
mappedByteBuffer.get(b);
} else {
mappedByteBuffer.get(new byte[length - i]);
}
}
long end = System.currentTimeMillis();
System.out.println("time is:" + (end - begin));
大明哥电脑是 32GB 的 MacBook Pro, 对 10k,1M,10M,100M,1G 五个文件的测试结果如下:
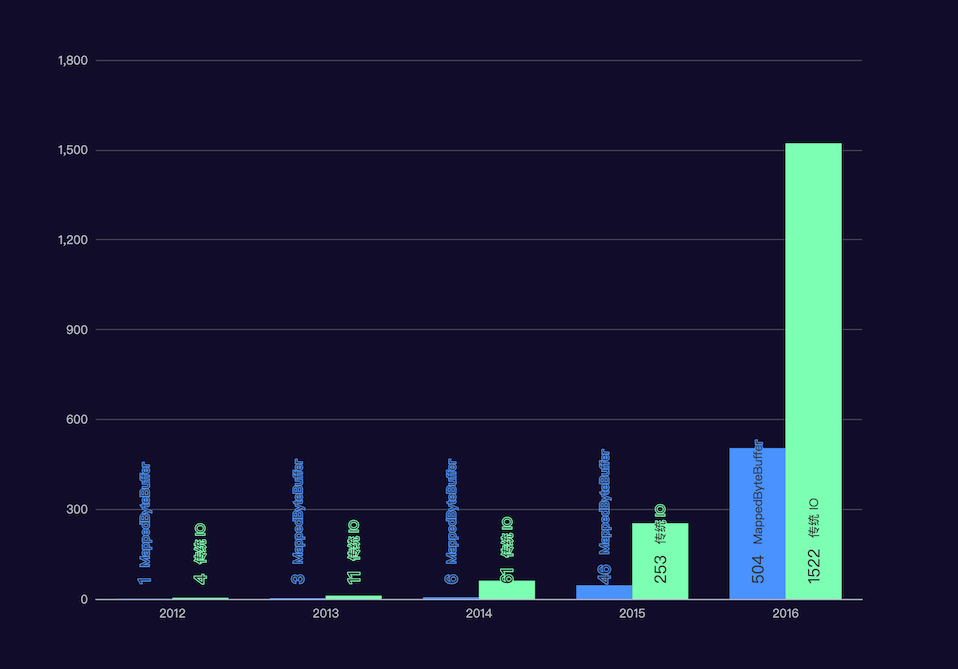
绿色是传统 IO 读取文件的,蓝色是使用 MappedByteBuffer 来读取文件的,从图中我们可以看出,文件越大,两者读取速度差距越大,所以 MappedByteBuffer 一般适用于大文件的读取。
DirectByteBuffer
父类 MappedByteBuffer 做了基本的介绍,且与传统 IO 做了一个对比,这里就不对 DirectByteBuffer 做介绍了,咱们直接撸源码,撸了源码后我相信你对堆外内存会有更加深入的了解。
DirectByteBuffer 是包访问级别,其定义如下:
class DirectByteBuffer extends MappedByteBuffer implements DirectBuffer {
// ....
}
分配内存
DirectByteBuffer 可以通过 ByteBuffer.allocateDirect(int capacity) 进行构造。
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
调用 DirectByteBuffer 构造函数:
DirectByteBuffer(int cap) {
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);// ①
long base = 0;
try {
base = unsafe.allocateMemory(size); // ②
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap)); // ③
att = null;
}
这段代码中有三个方法非常重要:
- ①
Bits.reserveMemory(size, cap) - ②
base = unsafe.allocateMemory(size) - ③
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
下面就这三段代码来逐个分析。
- ①
Bits.reserveMemory(size, cap)
这段代码有两个作用
- 总分配内存(按页分配)的大小和实际内存的大小
- 判断堆外内存是否足够,不够进行 GC 操作
static void reserveMemory(long size, int cap) {
if (!memoryLimitSet && VM.isBooted()) {
// 获取最大堆外可分配内存
maxMemory = VM.maxDirectMemory();
memoryLimitSet = true;
}
// 判断是否够分配堆外内存
if (tryReserveMemory(size, cap)) {
return;
}
final JavaLangRefAccess jlra = SharedSecrets.getJavaLangRefAccess();
// retry while helping enqueue pending Reference objects
// which includes executing pending Cleaner(s) which includes
// Cleaner(s) that free direct buffer memory
while (jlra.tryHandlePendingReference()) {
if (tryReserveMemory(size, cap)) {
return;
}
}
// trigger VM's Reference processing
System.gc();
// a retry loop with exponential back-off delays
// (this gives VM some time to do it's job)
boolean interrupted = false;
try {
long sleepTime = 1;
int sleeps = 0;
while (true) {
if (tryReserveMemory(size, cap)) {
return;
}
if (sleeps >= MAX_SLEEPS) {
break;
}
if (!jlra.tryHandlePendingReference()) {
try {
Thread.sleep(sleepTime);
sleepTime <<= 1;
sleeps++;
} catch (InterruptedException e) {
interrupted = true;
}
}
}
// no luck
throw new OutOfMemoryError("Direct buffer memory");
} finally {
if (interrupted) {
// don't swallow interrupts
Thread.currentThread().interrupt();
}
}
}
maxMemory = VM.maxDirectMemory(),获取 JVM 允许申请的最大 DirectByteBuffer 的大小,该参数可通过 XX:MaxDirectMemorySize 来设置。这里需要注意的是 -XX:MaxDirectMemorySize限制的是总 cap,而不是真实的内存使用量,因为在页对齐的情况下,真实内存使用量和总 cap 是不同的。
tryReserveMemory()可以统计 DirectByteBuffer 占用总内存的大小,如果发现堆外内存无法再次分配 DirectByteBuffer 则会返回 false,这个时候会调用 jlra.tryHandlePendingReference() 来进行会触发一次非堵塞的 Reference#tryHandlePending(false),通过注释我们了解了该方法主要还是协助 ReferenceHandler 内部线程进行下一次 pending 的处理,内部主要是希望遇到 Cleaner,然后调用 Cleaner#clean() 进行堆外内存的释放。
如果还不行的话那就只能调用 System.gc(); 了,但是我们需要注意的是,调用 System.gc(); 并不能马上就可以执行 full gc,所以就有了下面的代码,下面代码的核心意思是,尝试 9 次,如果依然没有足够的堆外内存来进行分配的话,则会抛出异常 OutOfMemoryError("Direct buffer memory")。每次尝试之前都会 Thread.sleep(sleepTime),给系统足够的时间来进行 full gc。
总体来说 Bits.reserveMemory(size, cap) 就是用来统计系统中 DirectByteBuffer 到底占用了多少,同时通过进行 GC 操作来保证有足够的内存空间来创建本次的 DirectByteBuffer 对象。所以对于堆外内存 DirectByteBuffer 我们依然可以不需要手动去释放内存,直接交给系统就可以了。还有一点需要注意的是,别设置 -XX:+DisableExplicitGC,否则 System.gc()就无效了。
- ②
base = unsafe.allocateMemory(size)
到了这段代码我们就知道了,我们有足够的空间来创建 DirectByteBuffer 对象了。unsafe.allocateMemory(size)是一个 native 方法,它是在堆外内存(C_HEAP)中分配一块内存空间,并返回堆外内存的基地址。
inline char* AllocateHeap( size_t size, MEMFLAGS flags, address pc = 0, AllocFailType alloc_failmode = AllocFailStrategy::EXIT_OOM){
// ... 省略
char*p=(char*)os::malloc(size, flags, pc);
// 分配在 C_HEAP 上并返回指向内存区域的指针
// ... 省略
return p;
}
- ③
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
这段代码其实就是创建一个 Cleaner 对象,该对象用于对 DirectByteBuffer 占用对堆外内存进行清理,调用 create() 来创建 Cleaner 对象,该对象接受两个参数
- Object referent:引用对象
- Runnable thunk:清理线程
调用 Cleaner#clean() 进行清理,该方法其实就是调用 thunk#run(),也就是 Deallocator#run():
public void run() {
if (address == 0) {
// Paranoia
return;
}
unsafe.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
方法很简单就是调用 unsafe.freeMemory() 释放掉指定堆外内存地址的内存空间,然后重新统计系统中的 DirectByteBuffer 的大小情况。
Cleaner 是 PhantomReference 的子类,PhantomReference 是虚引用,熟悉 JVM 的小伙伴应该知道虚引用的作用是跟踪垃圾回收器收集对象的活动,当该对象被收集器回收时收到一个系统通知,所以 Cleaner 的作用就是能够保证 JVM 在回收 DirectByteBuffer 对象时,能够保证相对应的堆外内存也释放。
释放内存
在创建 DirectByteBuffer 对象的时候,会 new 一个 Cleaner 对象,该对象是 PhantomReference 的子类,PhantomReference 为虚引用,它的作用在于跟踪垃圾回收过程,并不会对对象的垃圾回收过程造成任何的影响。
当 DirectByteBuffer 对象从 pending 状态 —> enqueue 状态,他会触发 Cleaner#clean()。
public void clean() {
if (!remove(this))
return;
try {
thunk.run();
} catch (final Throwable x) {
// ...
}
}
在 clean() 方法中其实就是调用 thunk.run(),该方法有 DirectByteBuffer 的内部类 Deallocator 来实现:
public void run() {
if (address == 0) {
// Paranoia
return;
}
// 释放内存
unsafe.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
直接用 unsafe.freeMemory() 释放堆外内存了,这个 address 就是分配堆外内存的内存地址。
关于堆外内存 DirectByteBuffer 就介绍到这里,我相信小伙伴们一定有所收获。下面大明哥介绍堆内内存:HeapByteBuffer。
