
Pre
我们平常做网络编程的时候都会碰到 Socket 对象 ,或者在配置代理的时候, 碰到配置 Socket 地址。 还经常会碰到 I/O 模型、异步编程、内存映射等概念。再往更深层次学习, 还会碰到 epoll/select 等编程模型。
有没有一种一团糟的感觉——其实学习好这些知识有一条主线,就是 抓住操作系统对 Socket 文件的设计 。
Socket 是什么?
首先,Socket 是一种编程的模型 。
下图中,从编程的角度来看,客户端将数据发送给在客户端侧的 Socket 对象 ,然后客户端侧的 Socket 对象将数据发送给服务端侧的 Socket 对象。
Socket 对象负责提供通信能力,并处理底层的 TCP 连接/UDP 连接 。
对服务端而言,每一个客户端接入,就会形成一个和客户端对应的 Socket 对象,如果服务器要读取客户端发送的信息,或者向客户端发送信息,就需要通过这个客户端 Socket 对象。

但是如果从另一个角度去分析,Socket 还是一种文件,准确来说是一种双向管道文件 。
什么是管道文件呢?管道会将一个程序的输出,导向另一个程序的输入。那么什么是双向管道文件呢?双向管道文件连接的程序是对等的,都可以作为输入和输出。
var serverSocket = new ServerSocket();
serverSocket.bind(new InetSocketAddress(80));
看起来我们创建的是一个服务端 Socket 对象,但如果单纯看这个对象,它又代表什么呢?如果我们理解成代表服务端本身合不合理呢——这可能会比较抽象,在服务端存在一个服务端 Socket。但 如果我们从管道文件的层面去理解它,就会比较容易了。其一,这是一个文件;其二,它里面存的是所有客户端 Socket 文件的文件描述符 。
当一个客户端连接到服务端的时候,操作系统就会创建一个客户端 Socket 的文件。然后操作系统将这个文件的文件描述符写入服务端程序创建的服务端 Socket 文件中。服务端 Socket 文件,是一个管道文件。如果读取这个文件的内容,就相当于从管道中取走了一个客户端文件描述符
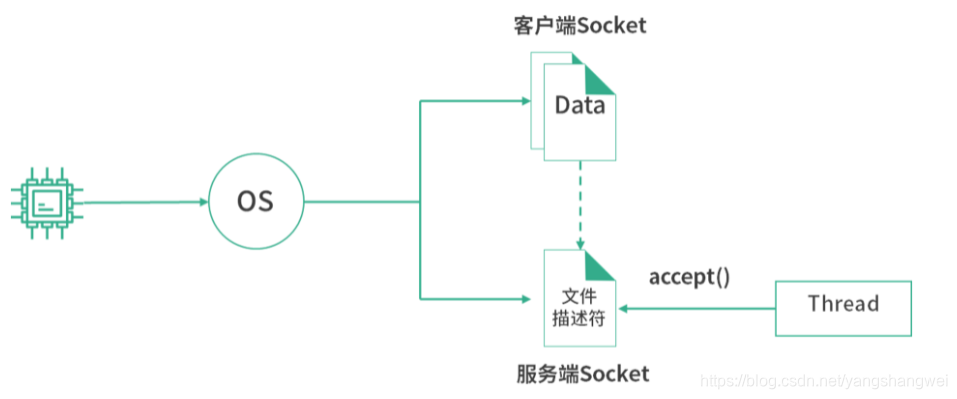
如上图所示,服务端 Socket 文件相当于一个客户端 Socket 的目录,线程可以通过 accept() 操作每次拿走一个客户端文件描述符。拿到客户端文件描述符,就相当于拿到了和客户端进行通信的接口。
前面我们提到 Socket 是一个双向的管道文件,当线程想要读取客户端传输来的数据时,就从客户端 Socket 文件中读取数据;当线程想要发送数据到客户端时,就向客户端 Socket 文件中写入数据。 客户端 Socket 是一个双向管道,操作系统将客户端传来的数据写入这个管道,也将线程写入管道的数据发送到客户端 。
总结下,Socket 首先是文件,存储的是数据。
对服务端而言,分成服务端 Socket 文件和客户端 Socket 文件。
服务端 Socket 文件存储的是客户端 Socket 文件描述符;
客户端 Socket 文件存储的是传输的数据。
读取客户端 Socket 文件,就是读取客户端发送来的数据;写入客户端文件,就是向客户端发送数据。对一个客户端而言, Socket 文件存储的是发送给服务端(或接收的)数据。
综上,Socket 首先是文件,在文件的基础上,又封装了一段程序,这段程序提供了 API 负责最终的数据传输。
服务端 Socket 的绑定
为了区分应用,对于一个服务端 Socket 文件,我们要设置它监听的端口。比如 Nginx 监听 80 端口、Node 监听 3000 端口、SSH 监听 22 端口、Tomcat 监听 8080 端口。端口监听不能冲突,不然客户端连接进来创建客户端 Socket 文件,文件描述符就不知道写入哪个服务端 Socket 文件了。
这样操作系统就会把连接到不同端口的客户端分类,将客户端 Socket 文件描述符存到对应不同端口的服务端 Socket 文件中。
因此,服务端监听端口的本质,是将服务端 Socket 文件和端口绑定,这个操作也称为 bind 。有时候我们不仅仅绑定端口,还需要绑定 IP 地址。这是因为有时候我们只想允许指定 IP 访问我们的服务端程序。
扫描和监听
对于一个服务端程序,可以定期扫描服务端 Socket 文件的变更,来了解有哪些客户端想要连接进来。如果在服务端 Socket 文件中读取到一个客户端的文件描述符,就可以将这个文件描述符实例化成一个 Socket 对象。
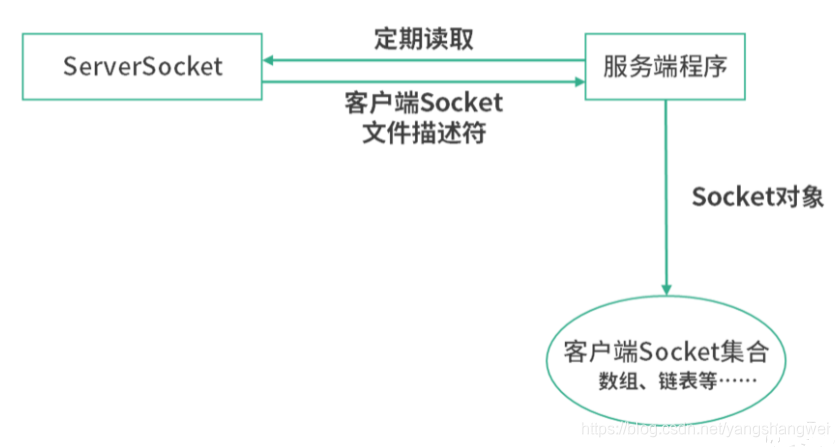
之后,服务端可以将这个 Socket 对象加入一个容器(集合),通过定期遍历所有的客户端 Socket 对象,查看背后 Socket 文件的状态,从而确定是否有新的数据从客户端传输过来。

上述的过程,我们通过一个线程就可以响应多个客户端的连接,也被称作 I/O 多路复用技术 。
响应式(Reactive)
在 I/O 多路复用技术中,服务端程序(线程)需要维护一个 Socket 的集合(可以是数组、链表等),然后定期遍历这个集合。这样的做法在客户端 Socket 较少的情况下没有问题,但是如果接入的客户端 Socket 较多,比如达到上万,那么每次轮询的开销都会很大。
从程序设计的角度来看,像这样主动遍历,比如遍历一个 Socket 集合看看有没有发生写入(有数据从网卡传过来),称为 命令式的程序 。这样的程序设计就好像在执行一条条命令一样,程序主动地去查看每个 Socket 的状态。
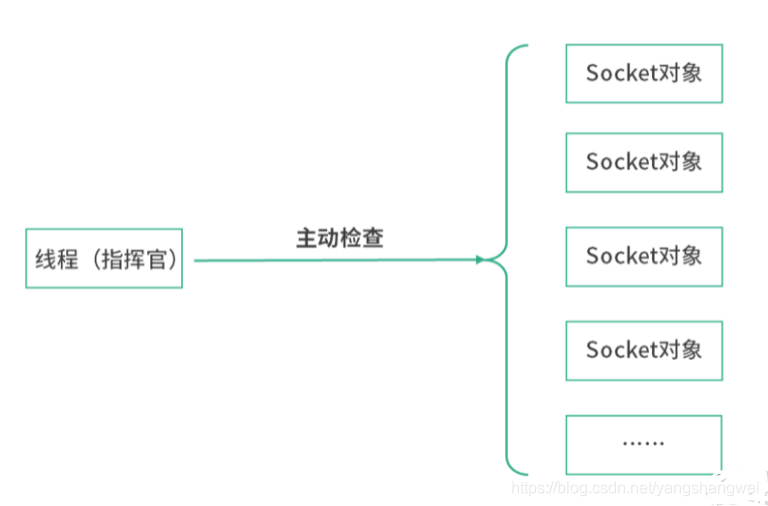
命令式会让负责下命令的程序负载过重,例如,在高并发场景下,上述讨论中循环遍历 Socket 集合的线程,会因为负担过重导致系统吞吐量下降 。
与命令式相反的是响应式(Reactive),响应式的程序就不会有这样的问题。在响应式的程序当中,每一个参与者有着独立的思考方式,就好像拥有独立的人格,可以自己针对不同的环境触发不同的行为。
从响应式的角度去看 Socket 编程,应该是有某个观察者会观察到 Socket 文件状态的变化,从而通知处理线程响应。线程不再需要遍历 Socket 集合,而是等待观察程序的通知 。
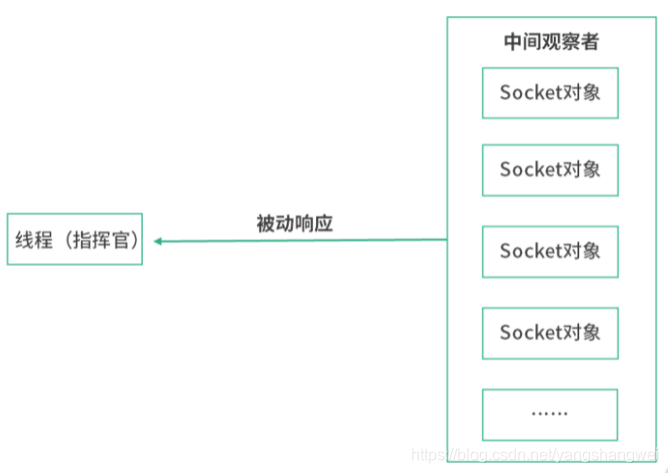
当然,最合适的观察者其实是操作系统本身,因为只有操作系统非常清楚每一个 Socket 文件的状态。原因是对 Socket 文件的读写都要经过操作系统。在实现这个模型的时候,有几件事情要注意。
-
线程需要告诉中间的观察者自己要观察什么,或者说在什么情况下才响应?比如具体到哪个 Socket 发生了什么事件?是读写还是其他的事件?这一步我们通常称为注册。
-
中间的观察者需要实现一个高效的数据结构(通常是基于红黑树的二叉搜索树)。这是因为中间的观察者不仅仅是服务于某个线程,而是服务于很多的线程。当一个 Socket 文件发生变化的时候,中间观察者需要立刻知道,究竟是哪个线程需要这个信息,而不是将所有的线程都遍历一遍
为什么用红黑树?
关于为什么要红黑树, 再仔细解释一下。考虑到中间观察者最核心的诉求有两个。
第一个核心诉求,是让线程可以注册自己关心的消息类型 。
比如线程对文件描述符 =123 的 Socket 文件读写都感兴趣,会去中间观察者处注册。当 FD=123 的 Socket 发生读写时,中间观察者负责通知线程,这是一个响应式的模型。
第二个核心诉求,是当 FD=123 的 Socket 发生变化(读写等)时,能够快速地判断是哪个线程需要知道这个消息
所以, 中间观察者需要一个快速能插入(注册过程)、查询(通知过程)一个整数的数据结构,这个整数就是 Socket 的文件描述符 。综合来看,能够解决这个问题的数据结构中,跳表和二叉搜索树都是不错的选择。
因此,在 Linux 的 epoll 模型中,选择了红黑树。红黑树是二叉搜索树的一种,红与黑是红黑树的实现者才关心的内容,对于我们使用者来说不用关心颜色,Java 中的 TreeMap 底层就是红黑树
总结
总结一下, Socket 既是一种编程模型,或者说是一段程序,同时也是一个文件,一个双向管道文件 。你也可以这样理解,Socket API 是在 Socket 文件基础上进行的一层封装,而 Socket 文件是操作系统提供支持网络通信的一种文件格式。
在服务端有两种 Socket 文件,每个客户端接入之后会形成一个客户端的 Socket 文件,客户端 Socket 文件的文件描述符会存入服务端 Socket 文件。通过这种方式,一个线程可以通过读取服务端 Socket 文件中的内容拿到所有的客户端 Socket。这样一个线程就可以负责响应所有客户端的 I/O,这个技术称为 I/O 多路复用。
主动式的 I/O 多路复用,对负责 I/O 的线程压力过大,因此通常会设计一个高效的中间数据结构作为 I/O 事件的观察者,线程通过订阅 I/O 事件被动响应,这就是响应式模型。在 Socket 编程中,最适合提供这种中间数据结构的就是操作系统的内核,事实上 epoll 模型也是在操作系统的内核中提供了红黑树结构。
QA epoll 为什么用红黑树?
在 Linux 的设计中有三种典型的 I/O 多路复用模型 select、poll、epoll。
select 是一个主动模型,需要线程自己通过一个集合存放所有的 Socket,然后发生 I/O 变化的时候遍历 。在 select 模型下,操作系统不知道哪个线程应该响应哪个事件,而是由线程自己去操作系统看有没有发生网络 I/O 事件,然后再遍历自己管理的所有 Socket,看看这些 Socket 有没有发生变化。
poll 提供了更优质的编程接口,但是本质和 select 模型相同 。因此千级并发以下的 I/O,你可以考虑 select 和 poll,但是如果出现更大的并发量,就需要用 epoll 模型。
epoll 模型在操作系统内核中提供了一个中间数据结构,这个中间数据结构会提供事件监听注册,以及快速判断消息关联到哪个线程的能力(红黑树实现) 。因此在高并发 I/O 下,可以考虑 epoll 模型,它的速度更快,开销更小。

Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
